")
")
Podstawy sieci z Cisco IOS. Moduł 3: Protokół IP i adresacja
IP (Internet Protocol) jest podstawowym protokołem, na którym opiera swoje działanie sieć Internet. Jego zadaniem jest transport danych od nadawcy do odbiorcy. Wchodzi w skład Internet Protocol Suite, będącego podstawą większości dzisiejszych sieci.
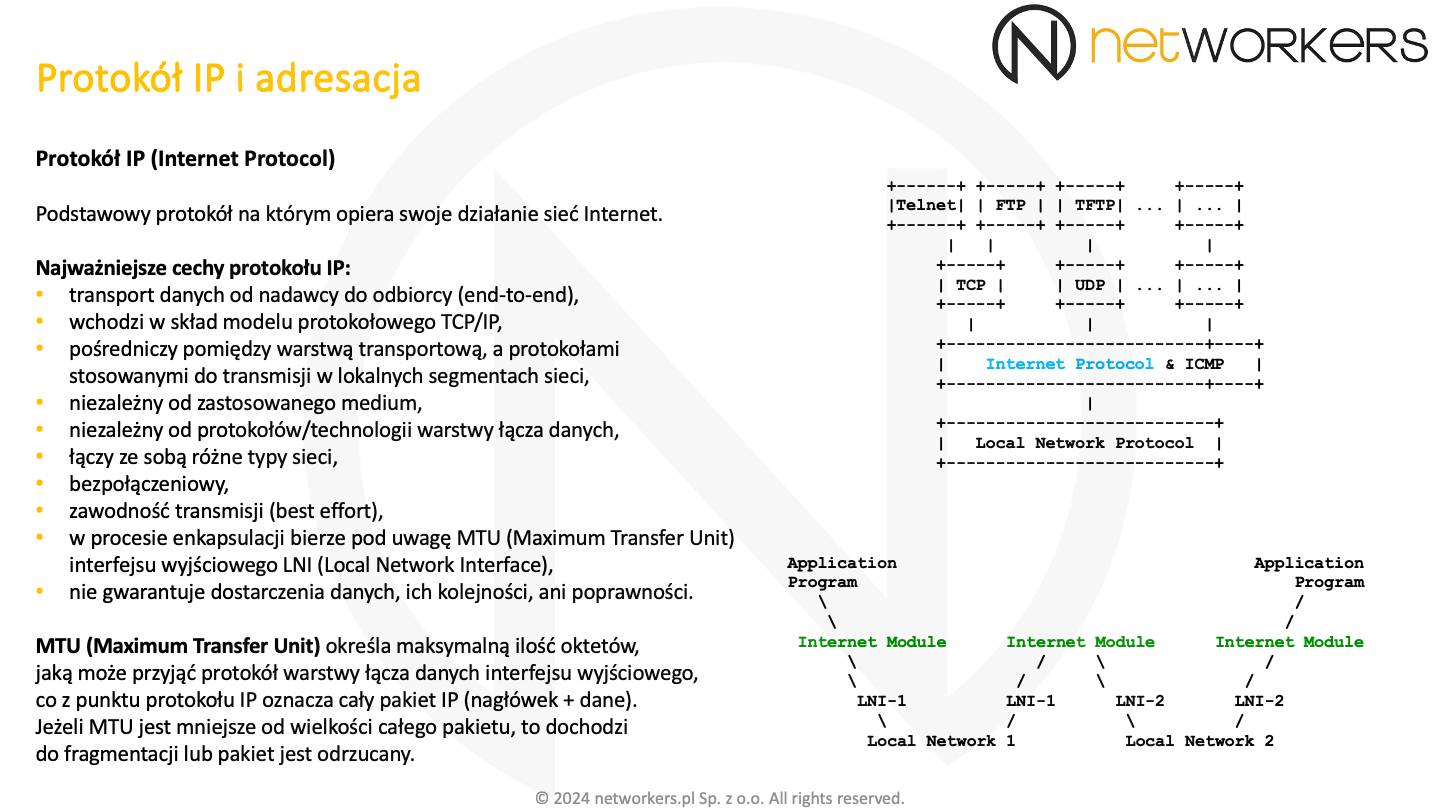
Protokół IP działa w warstwie trzeciej modelu OSI/ISO. Pośredniczy w transmisji pomiędzy protokołami warstwy transportowej, a protokołami warstwy łącza danych, które to wykorzystywane są do przesyłu w lokalnych segmentach sieci. Sprawia to, że jest on w pełni niezależny od zastosowanego medium fizycznego i technologii warstwy łącza danych.
Protokół IP działa tak samo w przypadku transmisji bezprzewodowej, jak i przewodowej. Dla protokołu IP nie ma znaczenia, czy użyty został kabel miedziany czy światłowód. Działa tak samo, bez względu na to czy technologią warstwy łącza danych jest PPP, Ethernet, Token Ring, Wireless LAN (Wi-Fi) czy Frame Relay.
Dzięki temu wykorzystywany jest on do łączenia ze sobą różnego rodzaju sieci, które tworzą sieć Internet.
Powodem popularności protokołu IP jest jego prostota. Protokół IP niczego nie gwarantuje. Ani dostarczenia pakietów, ani tego czy dotrą one w odpowiedniej kolejności, ani czasu w jakim zostaną dostarczone, ani nawet tego, że dane nie zostaną uszkodzone podczas transmisji. Aby tego było mało, jest on protokołem bezpołączeniowy. Nie przetrzymuje żadnych informacji na temat pakietów, jakie udało się przesłać. Przed wysłaniem pakietu nie jest też sprawdzane, czy odbiorca jest gotowy do ich odbioru.
Nie jest to zbyt dobra reklama dla protokołu IP. Wydawać się może to dość kontrowersyjne, gdyż przy użyciu tego protokołu przesyłana jest bardzo duża ilość ważnych informacji. Niemniej, takie właśnie działanie jest wielką zaletą protokołu IP. Jest on sam w sobie bardzo prosty co sprawia, że nadaje się do przenoszenia każdego rodzaju ruchu. W zależności od dodatkowych potrzeb, protokół IP obudowany jest innymi mechanizmami i protokołami wchodzącymi w skład Internet Protocol Suite.
Na poziomie warstwy trzeciej, każdy z pakietów IP obsługiwany jest na każdym z kolejnych urządzeń w pełni niezależnie od pozostałych. Tak więc, gdybyśmy wysłali dwa pakiety do tego samego węzła w sieci, jeden po drugim, to mogą one podróżować różnymi trasami. W wyniku tego, mogą one dotrzeć do odbiorcy w odwrotnej kolejności. Podobnie w drugą stronę. Dla pakietu wysłanego w odpowiedzi nie ma pewności, iż będzie on przesyłany tą samą drogą, jaką wcześniej otrzymany pakiet. Informacje o podróży pakietu nie są nigdzie zapisywane i przetrzymywane. Podejście takie ma swoje zalety. Sieć oparta o IP może rozkładać obciążenie na wielu trasach i być odporna na awarie pojedynczych połączeń.
Protokół IP stara się dostarczyć pakiet do odbiorcy, ale jeżeli z jakiś powodów nie będzie to możliwe, to po prostu go odrzuci. Nie zrobi nic więcej. Jest to też powodem dla którego często nazywany jest protokołem typu “best effort”. Jakakolwiek obsługa błędów musi być realizowana przez inne protokoły, jak ICMP (Internet Control Message Protocol). Wtedy, po usunięciu pakietu IP wygenerowana może zostać stosowna informacja ICMP do nadawcy wiadomości. Przy czym, otrzymanie takiego komunikatu nie wywoła retransmisji. Jest to komunikat czysto informacyjny. Wszelka niezawodność, jeżeli wymagana, musi być realizowana przez warstwy wyższe, jak np. protokół TCP (Transmission Control Protocol) czy SCTP (Stream Control Transmission Protocol).
Podczas procesu enkapsulacji, protokół IP zwraca uwagę na wartość MTU (Maximum Transfer Unit) interfejsu wyjściowego LNI (Local Network Interface). MTU określa maksymalną ilość oktetów, jaką może przyjąć protokół warstwy niższej. Jest to maksymalna wielkość całego pakietu IP (nagłówek razem z danymi). Jeżeli MTU LNI jest mniejsze od pakietu, to protokół IP musi dokonać fragmentacji. Pakiet zostanie odrzucony w przypadku, gdy fragmentacja nie jest możliwa.
Sprawdzenie MTU LNI realizuje Internet Module, zajmujący się obsługą protokołu IP. Dokonuje tego za każdym razem, kiedy pakiet jest przekazywany do kolejnego segmentu sieci. Każde LNI może obsługiwać różne wartości MTU. Zwykle, wynika to z obsługi różnych typów technologii, wykorzystywanych do transmisji w lokalnych segmentach sieci.
Powszechnie stosowaną wersją protokołu IP jest IPv4, czyli wersja 4. Oficjalną specyfikacją IPv4 jest dokument RFC 791. Format nagłówka IPv4 został zobrazowany na poniższym slajdzie.
Pierwszym polem w nagłówku jest 4 bitowe pole Version. Dla IPv4 posiada ono wartość 4. Kolejnym polem jest 4 bitowe pole IHL (Internet Header Length). Określa ono długość nagłówka IPv4 wyrażoną w słowach 4 oktetowych. Minimalna długość nagłówka IPv4 (bez opcji) to 20 oktetów. Pole IHL posiada wtedy wartość 5 (5 * 4 oktety = 20 oktetów). Maksymalna długość nagłówka z dodatkowymi opcjami, to 60 oktetów (15 * 4 oktetów = 60 oktetów). Wynika to z tego, że na dostępnych 4 bitach tego pola możemy zapisać tylko wartości z przedziału od 0 do 15. Dalej znajduje się 8 bitowe pole DSCP (Differentiated Services Code Point), które wykorzystywane jest przez mechanizmy zapewniające odpowiednią jakość usługi (QoS - Quality of Service).
Pole Total Length to 16 bitowe pole określające maksymalną długość całego pakietu IP w oktetach (nagłówek razem z danymi). Korzystając z pola IHL oraz Total Length w łatwy sposób można określić początek i koniec danych pakietu IP. Jest to istotne szczególnie wtedy, kiedy warstwa niższa dodaje do danych wypełnienie, aby utrzymać minimalną długość ramki (np. Ethernet, gdzie ramka musi zawierać minimum 46 oktetów danych). Maksymalna długość całego pakietu IPv4 razem z nagłówkiem to 65535 oktetów, przy czym pamiętać należy o ograniczeniu związanym z MTU. Jeśli MTU będzie mniejsze od wielkości całego pakietu, to dojdzie do fragmentacji lub pakiet zostanie odrzucony. W przypadku IPv4 minimalna wymagana wielkość MTU to 576 oktetów.

16 bitowe pole Identification jednoznacznie określa każdy wysłany pakiet. Najczęściej wartość tego pola rośnie o jeden, z każdym kolejno wysłanym pakietem. Pole to także wykorzystywane jest podczas procesu fragmentacji. Jego wartość jest kopiowana do każdego fragmentu, składające się na dany pakiet.
Pole Flags jest 3 bitowym polem. Pierwszy bit zawsze ustawiony jest na 0. Drugi bit to flaga DF (Don’t Fragment). Jeżeli ustawiona jest na 1, to pakiet nie może podlegać fragmentacji. W przypadku natrafienia na mniejsze MTU, pakiet z ustawionym bitem DF zostanie odrzucony. Trzeci bit jest flagą MF (More Fragments). Wartość 1 bitu MF oznacza, że fragment nie jest jeszcze ostatnim fragmentem pakietu. Budowa pola Flags została pokazana w prawym dolnym rogu slajdu, który widoczny jest powyżej.
Pole Fragment Offset jest 13 bitowym polem przesunięcia, wykorzystywanym do złożenia pakietu z powrotem w jedną całość. Zawiera przesunięcie fragmentu w stosunku do początku oryginalnego pakietu.
Jeżeli pakiet posiada zerową wartość pola Fragment Offset i flagę MF ma ustawioną na 0, to wiadome jest, że nie podlegał on fragmentacji. W przypadku IPv4, fragmentacja może zostać wykonana zarówno przez nadawcę, jak i na każdym kolejnym węźle na drodze pakietu. Dopuszcza się także przeprowadzenie fragmentacji na już wcześniejszych fragmentach. Informacje zawarte w nagłówku IP są wystarczające do złożenia pakietu w całość, nawet przy wielokrotnej fragmentacji. Złożeniem fragmentów zajmuje się dopiero odbiorca, gdzie realizuje to warstwa IP (jest to proces całkiem przeźroczysty dla wyższych warstw).
Każdy fragment staje się nowym pakietem i jest niezależnie routowany przez sieć. W związku z tym, następuje też odpowiednie dostosowanie innych pól, jak np. wartość pola Total Length, która wskazuje wielkość fragmentu, który stał się pakietem.
Fragmentacja sama w sobie nie jest powołana. Jeżeli zostanie zagubiony jeden fragment pakietu, trzeba niestety przesłać cały pakiet jeszcze raz. Protokół IP tego nie zrealizuje jako, że nie posiada on wbudowanych funkcji retransmisji. Fragmenty sprawiają też problemy przy filtrowaniu ruchu. Kiedy dojdzie do fragmentacji, tylko w pierwszym fragmencie pakietu zawarte są informacje na temat nagłówka protokołu warstwy wyższej, gdzie można znaleźć np. numery portów TCP/UDP. Powodem tego jest to, że fragmentacja odbywa się względem pola danych protokołu IP, a nagłówki protokołów warstw wyższych są dla IP danymi. Wszystkie fragmenty oprócz ostatniego przenoszą dane w wielokrotności 8 oktetów.
Pole Time to Live (skrótowo TTL) zapobiega krążeniu pakietów IP w pętli. Określa ono maksymalną liczbę routerów, przez które może przejść pakiet. Początkową wartość temu polu nadaje nadawca, a następnie jest ona zmniejszana o 1 przez każdy węzeł na drodze pakietu. Jest to pole 8 bitowe, więc maksymalna wartość TTL może wynosić 255. W zależności od implementacji, najczęściej wstawianymi wartościami początkowymi są 64, 128 lub 255. Kiedy pole to osiągnie wartość 0, pakiet IP jest usuwany z sieci, a nadawca stosownie informowany o tym fakcie przez protokół ICMP.
Pole Protocol wykorzystywane jest podczas procesu dekapsulacji. Wskazuje ono protokół warstwy wyższej, którego dane są przenoszone w pakiecie IP (np. 1 to ICMP, 6 to TCP, 17 to UDP). Jest to pole 8 bitowe.
16 bitowe pole Header Checksum jest sumą kontrolną samego nagłówka protokołu IP. Cały nagłówek dzielony jest na 16 bitowe słowa. Algorytm wykonuje ich sumę (pole Header Checksum równe jest zero podczas wyliczania sumy przez nadawcę). Następnie algorytm realizuje dopełnienie sumy (odwrócenie wartości, gdzie zera stają się jedynkami, a jedynki zerami) i wstawia uzyskaną wartość w polu Header Checksum. Kiedy odbiorca odbierze pakiet z prawidłowym nagłówkiem, to wyliczona suma kontrolna z dopełnieniem powinna zawierać same zera, a bez dopełnienia same jedynki (pole Header Checksum nie ma już wartości zerowej). Jeżeli tak nie jest, pakiet IP powinien zostać usunięty.
Pole Source Address to 32 bitowe pole w którym znajduje się adres IP nadawcy pakietu.
Pole Destination Address to 32 bitowe pole w którym znajduje się adres IP odbiorcy pakietu.
Ostatnim polem nagłówka jest pole Options. Zawiera ono dodatkowe opcje, jakie może przenosić nagłówek protokołu IP. Zawsze, kiedy opcje nie kończą się na granicy 32 bitów, wstawiane jest wypełnienie Padding składające się z samych 0. Wynika to z faktu, że pole długości nagłówka IP jest wielokrotnością 4 oktetów. Pola Options i Padding są opcjonalne (czyli może ich nie być).
Zanim zajmiemy się obecnie stosowanym sposobem podziału adresacji IP na podsieci, przejdziemy przez etapy pośrednie z jakimi do dziś mamy styczność. Wynika to ze zgodności wstecznej niektórych urządzeń i oprogramowania oraz co za tym idzie domyślnych wartości różnych poleceń i zmiennych interfejsów.
Zadaniem protokołu IP (Internet Protocol) jest zapewnienie komunikacji pomiędzy wszystkimi dołączonymi do sieci węzłami. Wymaga to jednoznacznej identyfikacji każdego dołączonego do sieci węzła. W tym celu stosowane są adresy IP.
W każdym pakiecie IP zawarte są pełne dane adresowe. Mówią one skąd (źródłowy adres IP) i dokąd (docelowy adres IP) taki pakiet jest routowany. Umożliwia to niezależną obsługę każdego pakietu, na każdym z kolejnych węzłów.

Adres IPv4 składa się z 32 bitów. Jest zatem liczbą dziesiętną w przedziale od 0 do 4,294,967,295. Tak też należy go traktować, jak jedną liczbę. Ze względu na trudności w zapamiętaniu i zarządzaniu tak wielką liczbą, powszechnie stosuje się zapis kropkowo dziesiętny. W tym celu 32 bitowa wartość została podzielona na 4 równe, odseparowane kropkami części, a następnie zapisana w postaci dziesiętnej. Każda powstała w ten sposób pozycja adresu IP zawiera 8 bitów i nazywana jest oktetem (przyjmuje wartości od 0 do 255). Oktety w adresie IP numerujemy od strony lewej do strony prawej, czyli 1.2.3.4, gdzie cyfra oznacza numer oktetu.
Wartość każdej z pozycji adresu IPv4 jest podstawą systemu 256 liczbowego. Wynika to z zapisu każdej pozycji na 8 bitach.
Zatem zamiana adresu IPv4 A.B.C.D z powrotem do jednej, 32 bitowej liczby dziesiętnej, powinna być realizowana zgodnie ze wzorem: A * 2563 + B * 2562 + C * 2561 + D * 2560. Zgodnie z tym, adres IPv4 148.152.32.115 jest liczbą 2,492,997,747.
Poniżej znajduje się sposób dojścia do wyżej przedstawionej liczby:
148 * 16777216 + 152 * 65,536 + 32 * 256 + 115 * 1 = 2,483,027,968 + 9,961,472 + 8,192 + 115 = 2,492,997,747
Do weryfikacji można posłużyć się poleceniem ping, któremu podać można adres IPv4 w postaci jednej dużej liczby:
PING 2492997747 (148.152.32.115) 56(84) bytes of data.
--- 2492997747 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
#
Chcąc dokonać konwersji w drugą stronę, najprościej jest liczbę 2,492,997,747 sprowadzić do postaci binarnej:
2,492,997,747 = 10010100100110000010000001110011
Następnie podzielić ją na 4 równe części i każdą z nich oddzielnie przekonwertować do postaci dziesiętnej:
10010100 . 10011000 . 00100000 . 01110011 = 148.152.32.115
Adres IP składa się z dwóch części. Część sieci, do której należą najbardziej znaczące bity adresu (bity idące od strony lewej do strony prawej) oraz części hosta, do której należą najmniej znaczące bity adresu (pozostałe bity, od strony prawej do lewej).
Początkowo, granica pomiędzy tymi częściami była twardo zdefiniowana i można było wyróżnić 3 klasy adresów IP:
- Klasa A - najbardziej znaczący 1 bit zawsze równy 0 (zero). Kolejne 7 bitów to część sieci. Pozostałe 24 bity to część hosta.
- Klasa B - najbardziej znaczące 2 bity równe binarnie 10 (jeden-zero). Kolejne 14 bitów to sieć i za nimi 16 bitów hosta.
- Klasa C - najbardziej znaczące 3 bity równe binarnie 110 (jeden-jeden-zero). Kolejne 21 bitów to sieć i za nimi 8 bitów hosta.
Routing pakietów był początkowo realizowany tylko w oparciu o pierwsze bity adresu IP (te definiujące jego klasę oraz fragment, który był częścią sieci). Był to tzw. routing klasowy. Jako, że część hosta nie była wykorzystywana, bity tej części były zawsze zapisywane samymi zerami. Tak powstał pierwszy typ adresu, adres reprezentujący sieć (network). Jest nim adres, który w części hosta posiada same zera i wykorzystywany jest on podczas realizacji funkcji routingu.
Bity hosta były używane dopiero w ostatnim etapie, podczas przekazywania pakietu do bezpośrednio dołączonego w sieci węzła.
Kiedy chcemy coś wysłać do wszystkich urządzeń w sieci, w tym celu wykorzystać możemy adres rozgłoszeniowy (broadcast). Wyróżnia się adres rozgłoszeniowy skierowany (directed broadcast) oraz adres rozgłoszeniowy ograniczony (limited broadcast). Adres rozgłoszeniowy skierowany to adres, który ma określoną część sieci, a w części hosta posiada same jedynki. Adres rozgłoszeniowy ograniczony to adres, którego wszystkie 32 bity ustawione są na jeden - 255.255.255.255.
Kiedy chcemy nadać coś do wszystkich hostów w znanym nam segmencie sieci, posłużyć się możemy adresem rozgłoszeniowym skierowanym. Jest to adres, który może być routowany w sieci IP. Przy czym, często ze względów bezpieczeństwa ruch do tego adresu nie jest wpuszczany do lokalnych segmentów sieci.
Z adresu rozgłoszeniowego ograniczonego korzystamy, kiedy chcemy wysłać coś do wszystkich hostów w lokalnym segmencie sieci. Nie ma dla nas znaczenia, jaki jest adres sieci lokalnego segmentu. Często go jeszcze nie znamy. Ruch zaadresowany na ten adres nigdy nie jest przekazywany do innych segmentów sieci. Do protokołów, które korzystają z tego adresu należy m.in. ARP i DHCP.
Pozostałe adresy IP w danej sieci (wykluczamy adres sieci i rozgłoszeniowy) są adresami skierowanymi (unicast). Posiadają one w części hosta wartości różne od samych zer i samych jedynek. Adresy te przypisywane są kolejnym hostom i wykorzystywane są do ich jednoznacznej identyfikacji. Co prawda, niektóre z tych adresów unicast mogą być też adresami anycast, ale o tym trochę niżej.
Wracając do naszego adresu 148.152.32.115 widać, że jego pierwsze 2 bity mają wartość 10 (jeden-zero). Oznacza to, że należy on do klasy B. Ostatnie 16 bitów w klasie B jest częścią hosta. Tak więc adres 148.152.0.0 jest adresem sieci, a adres 148.152.255.255 jest adresem rozgłoszeniowym (directed broadcast). Wszystkie pozostałe adresy w przedziale od 148.152.0.0 do 148.152.255.255 są adresami skierowanymi, które można przypisywać hostom.
W sieci IPv4 mamy do czynienia z 4 typami transmisji danych:
- transmisją skierowaną (unicast),
- transmisją rozgłoszeniową (broadcast),
- transmisją grupową (multicast),
- transmisją do jeden z wielu (anycast).
Najbardziej powszechnym typem transmisji, jest transmisja skierowana (często można spotkać się ze zwrotem “unicastowa”). Używana jest ona do przesyłu danych pomiędzy dwoma hostami. Dotyczy to trybu klient-serwer oraz peer-to-peer. Podczas transmisji skierowanej, jako adres źródłowy i docelowy wykorzystywane są adresy unicast.
Z transmisji rozgłoszeniowej korzystamy, kiedy chcemy nadać coś do wszystkich hostów w danej sieci lub nie wiemy, na którym z nich znajduje się określona usługa. Adresem źródłowym jest adres hosta. W przypadku, kiedy jeszcze nie zna on swojego adresu, jest nim adres składający się z samych zer - 0.0.0.0. Adresem docelowym jest adres rozgłoszeniowy.
Pamiętać należy, że pakiet rozgłoszeniowy zawsze trafia do wszystkich hostów w segmencie sieci. Stąd nie zawsze użycie tej transmisji jest efektywne. Przykładem może być chęć wysłania pakietu, tylko do określonej grupy odbiorców. Niestety, w przypadku rozgłaszania wszystkie stacje w sieci będą musiały taki pakiet przetworzyć. Zostanie on przekazany przez kartę sieciową stacji do CPU, który to dopiero podejmie dalszą decyzję na temat tego co z tym pakietem zrobić. Transmisja skierowana w takim zastosowaniu także się tutaj nie sprawdza. Wymaga ona wysłania oddzielnego pakietu, do każdego z uczestników grupy. Jest to mało efektywne. Rozwiązaniem problemu jest trzeci typ transmisji, zwany transmisją grupową.
Transmisja grupowa (często można spotkać się ze zwrotem “multicastowa”), umożliwia nadanie pakietu do określonej grupy hostów. Adresem źródłowym jest tutaj zawsze adres unicastowy. Adresem docelowym jest adres IP specjalnego typu, nazywany adresem multicast lub adresem multicastowym.
Adresy multicastowe należą do czwartej klasy adresowej, klasy D. Mają one 4 najbardziej znaczące bity zawsze równe binarnie 1110 (jeden-jeden-jeden-zero). Pozostałe 28 bitów definiuje kolejne adresy grupowe. Nie ma w tej klasie żadnego podziału na część sieci i hosta. Adresy są jedynie pogrupowane ze względu na ich przeznaczenie.
Transmisja anycastowa korzysta z normalnych adresów unicastowych. Nie ma w niej znaczenia, które z wielu urządzeń o tym samym adresie IP obsłuży nadesłany pakiet. Jest on przesyłany do tego urządzenia, które jest najbliżej względem tablicy routingu. Adres anycast wykorzystywany jest jako adres docelowy. Najczęstsze wykorzystanie tych adresów jest dla prostych bezstanowych usług, jak m.in. obsługa zapytań DNS, funkcja routera relay dla usługi 6to4, redundantnych VTEP czy nawet bramy domyślnej.
Istnieje jeszcze jedna klasa adresowa, klasa E. Pierwsze 4 najbardziej znaczące bity zawsze są równe binarnie 1111 (jeden-jeden-jeden-jeden). Klasa ta nie ma obecnie żadnego zastosowania. Poniżej znajduje się zestawienie omówionych wyżej klas adresowych. Taki podział nie skalował się zbyt dobrze, co doprowadziło do powstania FLSM, VLSM i CIDR.
Nie od razu podział na podsieci był tak elastyczny jak obecnie. Zanim pojawił się VLSM i CIDR mieliśmy okres przejściowy, w którym protokoły routingu nie potrafiły jeszcze przenosić informacji o masce podsieci czy długości prefiksu. Dominował wtedy podział klasowy oraz podział z użyciem FLSM. Do dziś na wielu urządzeniach dostępne są jeszcze protokoły routingu posiadające takie ograniczenia, stąd warto poruszane tutaj zagadnienia chociaż kojarzyć.
Podział klasowy nie skalował się zbyt dobrze. Załóżmy, że potrzebujemy zbudować sieć, w której będzie 300 węzłów. Sieć klasy C jest zbyt mała, gdyż ma tylko 8 bitów w części hosta. Mamy 256 możliwości z czego dwie trzeba zarezerwować dla adresu sieci i rozgłoszeniowego. Zostają 254 użyteczne adresy IP. Zmuszeni jesteśmy do zastosowania sieci klasy B. Mamy tam aż 16 bitów w części hosta, co daje 65,534 użyteczne adresy. Jako, że potrzebujemy tylko 300, to 65,234 adresy pozostaną niewykorzystane.
Sztywny podział klasowy szybko został uznany za mało wydajny i elastyczny. Aby zaadresować jego ograniczenia, wprowadzone zostało pojęcie podsieci i maski podsieci. Maska podsieci wyznacza granicę pomiędzy częścią sieci i hosta w adresie IP. Jest ona wartością 32 bitową, w której jedynki oznaczają część sieci, a zera część hosta. Tak samo jak adres IP, maska została podzielona na cztery oktety i zapisana w postaci kropkowo dziesiętnej.
Wróćmy do naszego adresu IP 148.152.32.115. Jest to adres klasy B, zatem jego domyślną maską jest:
- kropkowo dziesiętnie 255.255.0.0,
- binarnie 11111111.11111111.00000000.00000000.
Maska podsieci ma jeszcze jedną ciekawą właściwość. Kiedy wykonamy logiczną operację AND na adresie IP i masce podsieci, otrzymamy adres podsieci. Wynika to z tego, że maska podsieci przepisze nam część sieci i wyzeruje część hosta. Po wykonaniu operacji AND zostaną przepisane tylko te wartości z adresu IP, gdzie znajdują się jedynki:
10010100.10011000.00100000.01110011
11111111.11111111.00000000.00000000
———————————————————————————————————
10010100.10011000.00000000.00000000
Wartość 10010100.10011000.00000000.00000000 jest adresem IP 148.152.0.0, czyli adresem podsieci, do której należy wcześniej wybrany przez nas adres IP.
Wszystkie hosty w tej samej podsieci muszą mieć takie same najbardziej znaczące bity. Są nimi bity przynależne do części sieci. Sprawia to, że maska podsieci zawsze posiada ciągłą ilość jedynek od strony lewej do strony prawej.
Przypadłość ta, pozwoliła na użycie prostszego zapisu maski podsieci. Zapisu z użyciem prefiksu. Prefiks oznacza ilość jedynek od strony lewej do strony prawej lub ilość bitów, jaka należy do części sieci. Długość prefiksu podaje się po znaku slash "/". Korzystając z prefiksu, maskę podsieci 255.255.0.0 można zapisać w o wiele krótszej formie, to jest /16.
Zapis z użyciem prefiksu nazywany jest też notacją CIDR (Classless Inter-Domain Routing).
W podziale klasowym granica pomiędzy częścią sieci i hosta wyznaczana jest na podstawie wartości pierwszego oktetu. Można zatem mówić o domyślnej masce, wynikającej z klasy adresu. Dla sieci klasy A jest to 255.0.0.0 lub /8, dla klasy B 255.255.0.0 lub /16, a dla sieci klasy C 255.255.255.0 lub /24.
Maska podsieci nie musi być ograniczona klasą adresu. Można ją wydłużyć, przenosząc bity z części hosta do części sieci. W ten sposób dochodzi do podziału na podsieci, gdzie jedną sieć klasową dzielimy na mniejsze części, zwane podsieciami. Początkowo wszystkie podsieci musiały być tej samej wielkości, stąd podział ten nazywany był FLSM (Fixed Length Subnet Masking).
Związane to było z routingiem klasowym, który nie przenosił informacji na temat długości prefiksu (maski podsieci). Otrzymując w aktualizacji sam prefiks (np. 148.152.32.0), nie jesteśmy w stanie stwierdzić gdzie znajduje się w nim granica pomiędzy częścią sieci, a częścią hosta. Przyjęto więc zasadę, że wszystkie podsieci składające się na jedną sieć główną (wynikającą z klasy adresu), muszą posiadać tą samą długość prefiksu. Dzięki temu, dla wszystkich odbieranych prefiksów router mógł zastosować maskę z interfejsu, na którym odebrał aktualizację. Było to kolejnym ograniczeniem FLSM. Interfejs, na którym odbierana była informacja o podsieciach, musiał należeć do tej samej sieci głównej co te podsieci. Bez tego nie był w stanie poprawnie zinterpretować tych informacji. W praktyce oznaczało to, że podzielona na podsieci sieć główna musiała być ciągła, czyli nie można było jej przedzielić inną czy innymi sieciami głównymi (zarówno z tej samej klasy, jak i innej klasy adresowej).
Na samym początku istniało jeszcze kilka innych restrykcji. Nie można było korzystać z pierwszej i ostatniej podsieci. Pierwsza podsieć posiadała taki sam adres sieci, jak sieć główna. Ostatnia podsieć posiadała taki sam adres rozgłoszeniowy, jak sieć główna. Mogło prowadzić to do niejednoznaczności. W praktyce routing klasowy świetnie sobie z tym radził, a podejście to prowadziło do marnowania adresów IP. W związku z tym, zdecydowano się w późniejszym etapie na wykorzystanie wszystkich podsieci. Jeszcze dziś, w interfejsie CLI niektórych urządzeń można znaleźć polecenia do zmiany tego zachowania.
Podczas podziału na podsieci z wykorzystaniem FLSM należy najpierw zastanowić się nad potrzebną ilością podsieci. Wszystkie muszą mieć taką samą wielkość, czyli długość prefiksu. Stąd każda z podsieci będzie musiała pomieścić tyle samo hostów. Dokładnie tyle, ile znajdować się będzie w największym segmencie sieci.
Załóżmy, że dysponujemy jednym adresem klasy B 148.152.0.0/16 i chcemy utworzyć 5 podsieci. Aby zacząć, trzeba określić ile bitów z części hosta powinno zostać przeznaczone na podsieci. Najprościej jest skorzystać z poniższego równania:
5 ≤ 2N, gdzie N jest szukaną przez nas liczbą bitów. 22 to 4, więc to za mało. 23 to 8, więc spełnia nasze wymagania.
Tak więc potrzebne będą nam 3 bity. Możemy zapisać na nich 8 podsieci. Wydłużamy nasz prefiks /16 o 3 bity i w ten sposób otrzymujemy nowy /19. W części hosta pozostaje nam 13 bitów (32 - 19 = 13), które dają możliwość zaadresowania 8,192 adresów w każdej z podsieci. Z tego oczywiście dwa z nich, adres sieci i rozgłoszeniowy nie mogą zostać wykorzystane do adresowania hostów.
Nasz podział sieci klasy B 148.152.0.0/16 na podsieci o stałej długości wygląda następująco:

Jak to szybko sprawdzić?
Adres IP to jedna 32 bitowa liczba, podzielona tylko w zapisie dla naszej wygody. Wiemy, że w części hosta jest 13 bitów. 213 = 8,192. Zatem adresy dla każdej kolejnej podsieci będą rosły co 8,192 (adres podsieci, pierwszy adres użyteczny, ostatni adres użyteczny i adres rozgłoszeniowy). Wiemy już że adres A.B.C.D można odczytywać jako jedną liczbę: A * 2563 + B * 2562 + C * 2561 + D * 2560. Podstawą w zapisie kropkowo dziesiętnym jest liczba 256. 8,192 nie jest podzielne bez reszty ani przez 2563, ani przez 2562. Za to 8,192/2561 daje nam 32. Tak więc, w każdej kolejnej podsieci, trzeci oktet (C) adresu IP powinien zwiększać się o 32. Widać, że tak jest zarówno dla adresu reprezentującego podsieć, jak i dla zakresu użytecznych adresów i adresu rozgłoszeniowego.
Aktualnie, na wszystkich nowych urządzeniach działa domyślnie routing bezklasowy ale istnieje możliwość zmiany tego zachowania. Routing klasowy ograniczał wygodny i efektywny sposób zarządzania adresami IP. Niezbędna była zmiana na skutek której, powstał routing bezklasowy - CIDR (Classless Inter-Domain Routing).
Routing bezklasowy umożliwia routowanie pakietów bez zwracania uwagi na przynależność adresu do klasy. Wymaga to dodatkowej informacji, którą jest długość prefiksu (maska podsieci). Zapis maski w formie długości prefiksu pojawił się razem z CIDR, stąd często określany jest notacją CIDR. W routingu klasowym, informacje potrzebne do routowania były zaszyte w samym prefiksie (jego pierwsze bity). CIDR wymaga, aby tablice i algorytmy routowania wspierały podejmowanie decyzji w oparciu o prefiks i jego długość. Również protokoły routingu bezklasowego muszą przenosić razem z prefiksem informację o jego długości.
Routing realizowany przez CIDR odbywa się poprzez wybranie najdokładniejszego wpisu. Jest nim ten wpis, który posiada “najdłuższy prefiks”. Zatem dokładność określa długość prefiksu. Stąd, najdokładniejszym wpisem jest trasa o długości prefiksu /32, która określa pojedynczy adres IP hosta jako, że wszystkie bity prefiksu muszą się zgadzać. Zaś najmniej dokładnym wpisem jest trasa /0, która określa trasę domyślną. Pasuje do niej wszystko jako, że żaden z bitów prefiksu nie musi się zgadzać.
Oczywiście, aby adres IP przełączanego pakietu pasował do wpisu w tablicy routingu, musi zajść pomiędzy nimi dopasowanie odpowiedniej ilość bitów. Jest ona właśnie określona przez wspomnianą długość prefiksu.
Załóżmy, że router otrzymał pakiet z adresem docelowym 10.0.1.128, a tablica routingu wygląda jak poniżej:
Network | Next Hop
-----------------------------
10.0.1.128/32 | 192.0.2.2
10.0.1.0/24 | 192.0.2.3
10.0.0.0/16 | 192.0.2.4
10.1.0.0/16 | 192.0.2.5
0.0.0.0/0 | 192.0.2.6
Jako, że wybierany jest zawsze najdokładniejszy wpis, to pakiet zostanie przesłany do następnego przeskoku o adresie IP 192.0.2.2. Gdyby wpisu tego nie było w tablicy routingu, wybrany zostałby kolejny, czyli /24. Wpis o długości /0 wybierany jest tylko, kiedy żaden inny nie pasuje. Przykładem jego użycia byłby pakiet do adresu 10.2.2.2.
O ile takiego działania każdy się spodziewa, to dotyczy ono tylko routingu bezklasowego.
W routingu klasowym wszystkie podsieci składające się na daną sieć główną muszą być znane w tablicy routingu. W związku z tym, że w routingu klasowym nie wolno tworzyć podsieci nieciągłych, inne podsieci danej sieci głównej niż te znane routerowi nie mogły nigdzie indziej istnieć. Zatem nie ma sensu wysyłać takich pakietów z użyciem trasy domyślnej.
Dla przykładu, adres 10.0.1.128 i 10.2.2.2 należą do sieci głównej 10.0.0.0/8. W tablicy routingu routera, która znajduje się powyżej, znane są drogi do innych podsieci sieci głównej 10.0.0.0/8, stąd z założenia inne podsieci składające się na tą sieć główną nie istnieją. Stąd w routingu klasowym pakiet zaadresowany do 10.2.2.2 zostałby w naszym przypadku odrzucony. Natomiast pakiet zaadresowany do 11.2.2.2 zostałby wysłany zgodnie z trasą domyślną.
Dzięki CIDR dostępny stał się nowy podział na podsieci, zwany VLSM (Variable Length Subnet Masking). Jest on bardzo elastyczny. Nie ma w nim w ogóle pojęcia klasy adresowej i sieci głównej. Podsieci, czyli prefiksy i ich długości mogą być dowolnej wielkości.
Załóżmy, że dysponujemy jednym adresem klasy B: 148.152.0.0/16 i chcemy utworzyć 5 podsieci. Dzięki VLSM podsieci te mogą być bardziej dopasowane do naszych wymagań. Wiemy już, że możliwe jest utworzenie 5 podsieci w naszym zakresie adresowym. Zrobiliśmy to przy omawianiu FLSM. Doprecyzujemy zatem nasze pozostałe wymagania.
Określmy ile dokładnie adresów potrzebne będzie w każdej z 5 podsieci. Nasze wymagania to:
- Podsieć A: 100 adresów
- Podsieć B: 1000 adresów
- Podsieć C: 300 adresów
- Podsieć D: 256 adresów
- Podsieć E: 2 adresy
Podział na podsieci najlepiej jest rozpocząć od podsieci wymagającej największej ilości adresów. Na końcu zobaczymy dlaczego. Tak więc zacznijmy od sieci B, która potrzebuje 1000 adresów. Wyliczyć musimy ile bitów jest potrzebne w części hosta. Pamiętać należy o dodaniu 2 adresów jako, że w każdej podsieci mamy adresy “nieużyteczne”, którymi są adres sieci i rozgłoszeniowy. Zatem:
1000 + 2 ≤ 2N, gdzie N jest potrzebną liczbą bitów w części hosta. N = 10, gdyż 210 daje 1024.
Cały adres IP posiada 32 bity. Jeżeli w części hosta musi być 10 bitów, to w części sieci pozostaną 22 bity.
Zatem pierwsza podsieć to 148.152.0.0/22. Potrzebujemy jeszcze określić zakres użytecznych adresów IP i adres rozgłoszeniowy. Wiemy już, że adres A.B.C.D można odczytywać jako jedną liczbę, korzystając ze wzoru: A * 2563 + B * 2562 + C * 2561 + D * 2560. Podstawą w zapisie kropkowo dziesiętnym jest liczba 256. Wiemy, że dostępne są 1024 adresy. 1024 / 2561 daje 4. W ten sposób wiemy, że adresem kolejnej podsieci będzie 148.152.4.0. Numerację prowadzimy od zera, więc jest to kolejny wolny adres IP. Jako, że adres rozgłoszeniowy jest ostatnim adresem w podsieci, to będzie nim 148.152.3.255. Zakres użytecznych adresów IP, to przedział pomiędzy adresem sieci, a rozgłoszeniowym, czyli adresy od 148.152.0.1 do 148.152.3.254.
Druga pod względem wielkości podsieć wymagana 300 adresów IP.
300 + 2 ≤ 2N. N=9, gdyż 2N daje 512, co spełnia naszą nierówność.
I znowu, cały adres IP posiada 32 bity, a 9 z nich przeznaczamy na część hosta. W części sieci pozostaną nam 23 bity (32 - 9). Adresem drugiej podsieci jest 148.152.4.0/23, a podsieć ta pomieści 512 adresów z czego dwa są nieużyteczne. 512 / 2561 daje 2. Tak więc prefiksem kolejnej podsieci będzie 148.152.6.0, a jego długość zależna będzie od ilości potrzebnych adresów. Adresem rozgłoszeniowym będzie 148.152.5.255. Zakres adresów użytecznych zawiera się w przedziale od 148.152.4.1 do 148.152.5.254.
Trzecia podsieć wymaga 256 adresów IP do zaadresowania urządzeń. Tutaj szczególnie należy pamiętać o 2 dodatkowych adresach. 256 adresów można zapisać na 8 bitach. 256 + 2 potrzebują już 9 bitów. Zatem nasza trzecia podsieć będzie takiej samej wielkości jak druga. Jej adres sieci to 148.152.6.0/23. Pierwszym adresem użytecznym będzie 148.152.6.1, a ostatnim użytecznym adresem 148.152.7.254. Adresem rozgłoszeniowym tej podsieci jest 148.152.7.255.
Kolejny wolny prefiks to 148.152.8.0. Aby wyliczyć jego długość, znowu wykorzystujemy naszą nierówność:
100 + 2 ≤ 2N. N równe jest 7. Zabierając 7 bitów na cześć hosta, pozostaje nam 25 na część sieci. Zatem naszą kolejną podsiecią będzie 148.152.8.0/25. Na 7 bitach zapisać można 128 możliwości, zatem kolejnym wolnym prefiksem stanie się 148.152.8.128. Adresem rozgłoszeniowym tej podsieci będzie 148.152.8.127 (ostatni dostępny adres IP ma zawsze w cześci hosta same jedynki). Zakres adresów użytecznych będzie w przedziale od 148.152.8.1 do 148.152.8.126.
Ostatnia podsieć wymaga 2 adresów. Doliczając do tego adres podsieci i adres rozgłoszeniowy, potrzebujemy ich 4. 2 + 2 ≤ 2N. Nasze N wynosi 2, więc na część hosta potrzebne nam będą tylko 2 bity. Pozostałe 30 bitów będzie należało do części sieci. Biorąc kolejny wolny prefiks, naszą podsiecią będzie 148.152.8.128/30. Są w niej tylko 4 adresy IP, więc kolejnym wolnym prefiksem będzie 148.152.8.132. Adres rozgłoszeniowy to 148.152.8.131, a użyteczne adresy to 148.152.8.129 i 148.152.8.130.
Nasz podział sieci 148.152.0.0/16 na podsieci o zmiennej długości wygląda następująco:

Kolejny wolny adres IP to 148.152.8.132. Niemniej, długość jego prefiksu nie może być dłuższa niż /30. Gdybyśmy chcieli dać długość /24, to w części hosta nie znajdowałyby się same zera, stąd musielibyśmy przeskoczyć od razu do 148.152.9.0/24, zostawiając w adresacji dziurę. Widać to ładnie niżej, po rozpisaniu adresu sieci i maski binarnie.
148.152.8.132 10010100.10011000.00001000.10000100
255.255.255.252 11111111.11111111.11111111.11111100
255.255.255.0 11111111.11111111.11111111.00000000
Jeżeli adresację rozpoczniemy od największej podsieci, unikniemy takiej sytuacji.
Powiedzieliśmy sobie wcześniej, że z każdej podsieci musimy wyłączyć dwa "nieużyteczne" adresy. Jednym jest adres sieci (same zera w części hosta), a drugim adres rozgłoszeniowy (same jedynki w części hosta). Wyjątkiem od tej reguły jest prefiks /31 (255.255.255.254), który został opisany w RFC 3021. W podsieci /31 istnieją tylko dwa adresy, jeden ma w części hosta 0, a drugi 1. Obydwa mogą być przypisane do urządzeń. Do obsługi ruchu rozgłoszeniowego wykorzystywany jest zawsze adres rozgłoszeniowy ograniczony (limited broadcast, czyli 255.255.255.255). Wynika to z braku adresu rozgłoszeniowego skierowanego (directed broadcast). Prefiks ten dedykowany jest dla połączeń point-to-point, gdzie istnieją tylko dwa końce połączenia. Jego celem jest zaoszczędzenie adresów IP. Wcześniejsza praktyka zakładała używanie prefiksów /30 (dwa adresy były marnowane niepotrzebnie) lub nienumerowanie takich interfejsów (utrudniało to zarządzanie i rozwiązywanie problemów).
Nowe podejście ma wiele zalet. Możliwe jest nie tylko tworzenie podsieci o dowolnej wielkości i układanie ich w nieciągły sposób. Dodatkowo stało się możliwe tworzenie tak zwanych “nadsieci”, czyli agregowanie prefiksów.
Ma to znaczący wpływ na wielkość dzisiejszych tablic routingu. Oczywiście wymaga to hierarchicznej dystrybucji adresów IP. Agregowane prefiksy muszą posiadać takie same najbardziej znaczące bity. Gdybyśmy chcieli dokonać agregacji dwóch podsieci 148.152.4.0/23 i 148.152.6.0/23, trzeba znaleźć ich wspólne najbardziej znaczące bity.
10010100 . 10011000 . 00000100 . 00000000 = 148.152.4.0/23
10010100 . 10011000 . 00000110 . 00000000 = 148.152.6.0/23
Nową długością prefiksu, będzie wspólna ilość bitów. Widać, że posiadają one wspólne 22 bity. Stąd nowym prefiksem, którym swoim zakresem pokryje dwie powyższe podsieci będzie 148.152.4.0/22.
Widać tutaj sporą elastyczność VLSM. Granica pomiędzy częścią sieci, a częścią hosta może być na dowolnym bicie. Cały adres IP jest tak naprawdę jedną dużą 32 bitową liczbą. Tworzenie podsieci lub grupowanie adresów sprowadza się do tego samego, określenia wspólnych najbardziej znaczących bitów.
Pomimo tego, że obecnie do adresowania IPv4 stosowany jest VLSM, to warto znać zagadnienia związane z klasowością i FLSM. Wynika to z domyślnego zachowania niektórych poleceń, protokołów oraz ich wartości domyślnych.
Przed kolejną porcją wiedzy zachęcamy do przećwiczenia i utrwalenia tej poznanej tutaj. Skorzystaj z naszych ćwiczeń!