")
")
Podstawy sieci z Cisco IOS. Moduł 2: Ethernet Switching
Powszechnie stosowane są dwa modele referencyjne, na których oparte są systemy do komunikacji. Ich celem jest podział procesu komunikacji na mniejsze i łatwiejsze do zdefiniowania warstwy. Każda z warstw ma jasno określone funkcje oraz metody interakcji i komunikacji z sąsiednimi warstwami. Sprawia to, że o wiele łatwiej da się tworzyć nowe i rozwijać istniejące protokoły czy standardy. Bez zmiany wszystkiego można skupić się na określonej warstwie i wygodnie wpasować w to co już jest. Zatem zmiana w warstwie trzeciej z IPv4 na IPv6 nie wymaga zmian w technologii Ethernet (warstwa druga) czy protokołach TCP i UDP (warstwa czwarta). Modele referencyjne są też przydatne przy zrozumieniu i omawianiu procesu komunikacji.
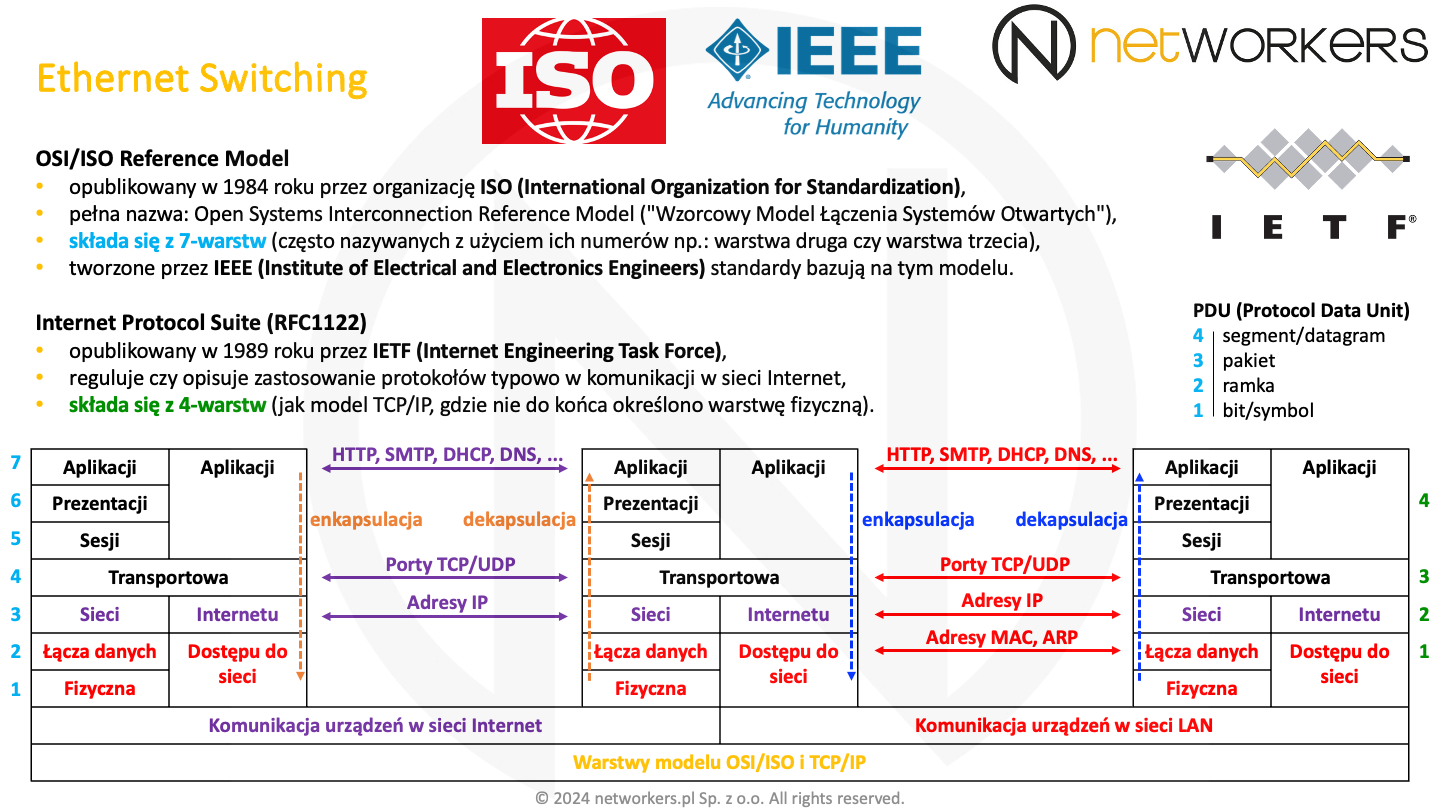
Internet Protocol Suite został opisany przez organizację IETF (Internet Engineering Task Force) w dokumencie RFC1122 w 1989 roku. Zarówno ten model, jak i dokumenty RFC (Request for Comments) publikowane przez IETF zawężają się do tego, co i jak powinno odbywać się w sieci Internet i powszechnie jest faktycznie stosowane. Zatem dla przykładu nie znajdziemy w nich wszystkich możliwych sposobów użycia podwarstwy IEEE 802.2 LLC (Logical Link Control), a jedynie te które bezpośrednio odnoszą się do tego, jak ta podwarstwa powinna być stosowana dla ruchu w sieci Internet. Niemniej, najczęściej dokładnie tak samo powinno się to odbywać w naszej sieci LAN (Local Area Network), gdyż jest ona najczęściej rozszerzeniem najpopularniejszej sieci, jaką jest dziś sieć Internet. Stąd zawarte tam informacje są zwykle wystarczające dla inżynierów sieciowych.
Zarówno Internet Protocol Suite, jak i model TCP/IP nie mają dokładnie zdefiniowanej warstwy fizycznej. To też jest powodem, dla którego niektórzy mówią o czterech, a inni o pięciu warstwach modelu TCP/IP. Piąta to ta fizyczna. Co do reszty, modele te są sobie bardzo bliskie i podobne. W nazwie modelu TCP/IP użyte zostały nazwy najpopularniejszych protokołów stosu TCP/IP, tj. protokołu TCP (Transmission Control Protocol) i IP (Internet Protocol). Oczywiście działa tam o wiele więcej protokołów.
Model OSI/ISO został opublikowany w 1984 roku przez organizację ISO (International Organization for Standardization). Jak wskazuje nazwa Open Systems Interconnection (OSI) Reference Model czy "Wzorcowy Model Łączenia Systemów Otwartych", celuje on o wiele szerzej. Model referencyjny OSI/ISO jest bardziej otwarty, jako że wychodzi ponad zastosowanie protokołów tylko w sieci Internet. Tworzone na jego bazie protokoły czy standardy są bardziej uniwersalne.
Organizacja IEEE (Institute of Electrical and Electronics Engineers) tworzy standardy bazujące właśnie na tym modelu. Dla przykładu standardy IEEE dotyczące sieci LAN, które zaczynają się od numerka 802 dotyczą warstwy pierwszej i drugiej modelu OSI/ISO. Opisane w dokumentach IEEE 802 standardy wykraczają poza to, co wymagane jest do komunikacji w sieci Internet.
Zarówno Internet Protocol Suite, jak i model TCP/IP definiują warstwę aplikacji, transportu, internetu i dostępu do sieci lub łącza. Za to w modelu OSI/ISO mamy warstwę aplikacji, prezentacji, sesji, transportu, sieci, łącza danych i fizyczną. W modelu OSI/ISO warstwy często nazywa się z użyciem ich numerów jak np. warstwa druga czy warstwa trzecia. Spotyka się również użycie skrótów, jak L2 czy L3 z angielskiego, odpowiednio Layer 2 czy Layer 3. Określenia te stosowane są często zamiennie.
W trakcie transmisji przez sieć dochodzi do procesu enkapsulacji, czyli zamykania PDU (Protocol Data Unit) warstwy wyższej w PDU warstwy niższej. PDU jest jednostką transmisji danej warstwy. Dla warstwy pierwszej są to bity i symbole, dla warstwy drugiej ramki, dla warstwy trzeciej pakiety, dla warstwy czwartej segmenty lub datagramy, a w warstwach wyższych z perspektywy inżyniera sieciowego są po prostu dane. W trakcie enkapsulacji, PDU warstwy wyższej traktowane jest w warstwie niższej jak dane, do których to dokłada ona swój nagłówek, tworząc swoje PDU. Proces odwrotny, który weryfikuje zgodność pól nagłówka i przekazuje zawartość pola danych do warstwy wyższej nazywany jest dekapsulacją.
Warstwa fizyczna określa m.in. parametry mechaniczne i elektryczne, w tym konkretne symbole kodowe, poziomy napięcia, rodzaj okablowania czy kształt i budowę złącza fizycznego. W warstwie tej wymieniane są bity lub symbole.
Warstwa łącza danych określa m.in. budowę ramki, sposób dostępu do medium i interakcji z warstwami wyższymi. Za sposób dostępu do medium, w tym stosowaną tam adresację odpowiada podwarstwa MAC (Media Access Control). Jest to dolna część warstwy łącza danych. Za komunikację z warstwami wyższymi odpowiada górna część warstwy łącza danych, która opisana została w dokumencie IEEE 802.2. Jest to podwarstwa LLC (Logical Link Control), która jest wspólna dla wielu technologii opisanych w standardach IEEE 802. Zatem warstwa łącza danych została tu podzielona na dwie podwarstwy. Ethernet został opisany w IEEE 802.3, gdzie jego specyfikacja dotyczy zarówno warstwy pierwszej, jak i drugiej. Inną technologią warstwy drugiej jest np. Token Ring opisany w IEEE 802.5 czy Wireless LAN (WLAN) opisany w IEEE 802.11. Patrząc na te technologie widać, że warstwa druga dotyczy tylko komunikacji w ramach jednego segmentu sieci, czyli pomiędzy dwoma interfejsami. W warstwie drugiej do komunikacji stosowane są adresy MAC. W warstwie tej wymieniane są ramki.
Warstwa sieci dotyczy komunikacja end-to-end czyli takiej, która wykraczać może poza pojedynczy segment sieci. Zatem to tutaj odbywa się routing. Mamy tu do czynienia z protokołem i adresami IPv4 i/lub IPv6. Tutaj też mówimy już o m.in. sieci Internet. Warstwa ta dotyczy także protokołów pomocniczych, jak m.in. ICMP czy ARP. W warstwie tej wymieniane są pakiety.
Warstwa transportowa udostępnia kanał komunikacyjny do wymiany danych pomiędzy aplikacjami czy usługami. Do wymiany informacji stosowane są porty. Działa w niej m.in. protokół TCP i UDP. Dla każdego z nich został przewidziany niezależny zakres portów 0-65535. Kanał komunikacyjny udostępniany przez protokoły tej warstwy może dodatkowo zapewniać m.in. obsługę błędów, segmentację danych, kontrolę przepływu czy kontrolę przeciążenia. Niemniej, nie jest to obowiązkowe i dla każdej aplikacji może być różne. W warstwie tej wymieniane są segmenty (przy TCP) lub datagramy (przy UDP).
Warstwa sesji zajmuje się zarządzaniem czy też obsługą kanałów komunikacyjnych. Zatem m.in. ustanawia, utrzymuje i zamyka sesje czy też kanały komunikacyje (mogą one działać w jednym lub dwóch kierunkach - Half Duplex/Full Duplex). Przykładem jest obsługa gniazda sieciowego, choć warstwa ta ma zdefiniowane nieco więcej zadań.
Szufladkowanie od tej warstwy nie jest już tak łatwe. Szczególnie dla inżyniera sieciowego. W ramach jednej aplikacji czy protokołu aplikacyjnego mogą być zaimplementowane funkcje warstwy sesji, prezentacji i aplikacji lub prezentacji i aplikacji.
Warstwa prezentacji określa format danych i zapewnia możliwość odtworzenia danych czy też ich czytelność po drugie stronie połączenia. W ramach tej warstwy system wysyłający dokonuje konwersji danych do formatu w jakim odbywa się transmisja, a system odbierający dokonuje konwersji danych do formatu akceptowalnego przez aplikację. W warstwie tej może odbywać się translacja danych (np. pomiędzy ASCII i EBCDIC), szyfrowanie, deszyfrowanie, kompresja i dekompresja danych.
Warstwa aplikacji udostępnia usługi sieciowe dla aplikacji. Jest miejscem gdzie odbywa się zwykle dużo innowacji. Udostępnia aplikacji m.in. funkcje wymiany plików, wiadomości, dostępu do bazy danych czy zdalnego terminala.
W dolnej części slajdu widać zarówno warstwy dostępne w Internet Protocol Suite, jak i modelu referencyjnym OSI/ISO. O ile ideą obu modeli jest podział procesu komunikacji na mniejsze elementy - sumarycznie pokrycie całego procesu komunikacji - to Internet Protocol Suite nie specyfikuje części fizycznej. A co do reszty, to widać tam które warstwy modelu referencyjnego OSI/ISO odpowiadają funkcjonalnie którym warstwą Internet Protocol Suite czy modelu TCP/IP.
Jak chodzi o technologię Ethernet, to jej działanie dotyczy warstwy 1 i 2 modelu OSI/ISO lub łącza danych w Internet Protocol Suite.
Ethernet od zawsze był postrzegany jako technologia sieci LAN (Local Area Network). Z czasem zaczął dominować w sieciach MAN (Metropolitan Area Network), a dziś można też go spotkać i w sieciach WAN (Wide Area Network). Nie ma wątpliwości, że to jedna z najbardziej popularnych i powszechnych technologii warstwy drugiej modelu OSI/ISO. Swoją popularność zawdzięcza w dużej mierze otwartości. Pierwsze technologie komunikacyjne były zamknięte. Nie można było ich od tak stosować, a na dodatek działały tylko w ramach własnościowych rozwiązań. Dzięki staraniom Roberta "Boba" Metcalfe tak się nie stało z Ethernet. Za powstanie technologii Ethernet przyjmuje się 22 maja 1973 roku, kiedy to została zmieniona jej nazwa z Alto Aloha Network na Ethernet.
W roku 1972 Boba Metcalfe stworzył w ośrodku Xerox PARC (Palo Alto Research Center) technologię umożliwiającą komunikację z prędkością 2,94Mbps pomiędzy drukarkami laserowymi, a stacjami roboczymi Alto typu PC firmy Xerox. Technologia ta bazowała na protokole ALOHA (Additive Links On-line Hawaii Area), dlatego i nazywała się właśnie Alto Aloha Network.
Norman Abramson rozpoczął prace nad protokołem ALOHA na Uniwersytecie Hawajskim w 1968 roku. Zadaniem tego protokołu było umożliwienie komunikacji pomiędzy wyspami Archipelagu Hawajskiego w ramach jednego współdzielonego kanału komunikacyjnego czy też w tym przypadku kanału radiowego. Skutkiem tych prac w 1971 roku protokół ten działał już produkcyjnie.
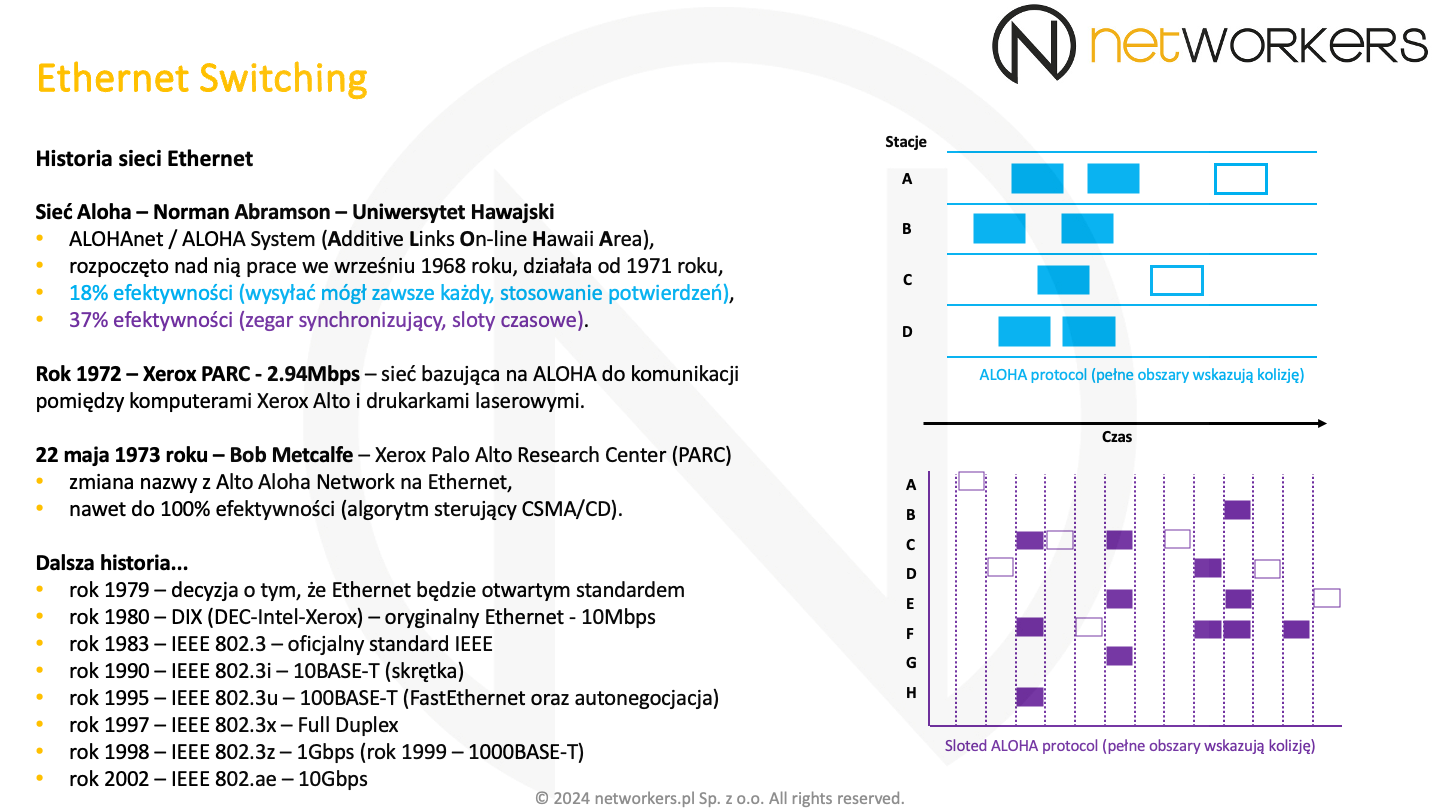
Pierwsza wersja protokołu ALOHA była bardzo prosta. Jej działanie obrazuje błękitny rysunek. Widać na nim też 4-stacje: A, B, C i D oraz oś czasu "idącą w prawo". Każda ze stacji mogła rozpocząć nadawanie w dowolnym momencie. Kiedy więcej niż jedna rozpoczęła nadawanie dochodziło do uszkodzenia sygnału, skutkiem czego odbiorca nie otrzymał komunikatu i nie wysłał do nadawcy potwierdzenia. Brak otrzymania potwierdzenia był jednoznaczny z potrzebą ponowienia transmisji. Odbywało się to po losowym czasie, tak by zminimalizować prawdopodobieństwo kolejnej kolizji. Niemniej, było to bardzo mało efektywne przy większej ilości stacji. Efektywność czy maksymalne wykorzystanie kanału radiowego wynosiło zaledwie 18%.
Na obu rysunkach wypełnione kolorem prostokąty obrazują miejsca, w których doszło do kolizji, skutkiem czego sygnał został uszkodzony. Puste prostokąty wskazują czystą transmisję, która poprawnie została nadana.
Aby poprawić efektywność do protokołu ALOHA zostały wprowadzone szczeliny czasowe. Na fioletowych rysunku możemy zobaczyć działanie Sloted ALOHA. Stacja mogła rozpocząć nadawanie tylko z początkiem danego slotu czasowego. Jeżeli tego nie zrobiła, musiała czekać na kolejny. Zmniejszyło to ilość kolizji czy zakłócających się transmisji i poprawiło efektywność do 37%.
Bob Metcalfe wprowadził szereg ulepszeń. Jego technologia korzystająca z współdzielonego medium, którym w tym przypadku był kabel, potrafiła nasłuchiwać przed rozpoczęciem transmisji, co minimalizowało występowanie kolizji. Został też do niej wprowadzony mechanizm wykrywania kolizji, dzięki któremu stacje wiedziały, że muszą ponowić transmisję. Stąd też nazwa mechanizmu CSMA/CD (Carrier Sense Multiple Access with Collision Detect), który działa w trybie Half Duplex. Modyfikacje te sprawiły, że wykorzystanie kanału mogło dochodzić nawet do 100%.
22 maja 1973 roku Bob Metcalfe zmienił nazwę tej technologii z Alto Aloha Network na Ethernet. Wydarzenie to miało sugerować, że była już ona o wiele bardziej zaawansowana i różna od protokołu ALOHA, a też stała się technologią z której będzie mógł korzystać każdy komputer, a nie tylko komputery Alto. W nazwie pojawia się słowo "ether", które ma określać medium przenoszące bity pomiędzy podłączonymi do niego stacjami. W roku 1978 jedynym właścicielem technologii Ethernet była ciągle tylko firma Xerox. W roku 1979 zapadła decyzja o otwarciu i rozpowszechnieniu technologii Ethernet, skutkiem czego w 1980 roku przez konsorcjum składające się z trzech firm: DEC, Intel i Xerox, został opublikowany pierwszy standard Ethernet dla 10Mbps. Standard ten znany jest też jako DIX Ethernet, od pierwszych liter tych trzech firm tworzących konsorcjum. Dalej standaryzacją technologii Ethernet zajęła się już organizacja IEEE. Skutkiem jej pracy w 1983 roku powstał wstępny standard IEEE 802.3.
Nie omawiamy w szczegółach pracy technologii Ethernet w trybie Half Duplex i co za tym idzie algorytmu backoff w CSMA/CD, mechanizmów obsługi kolizji dla 10/100Mbps czy też różnic implementacyjnych dla Half Duplex i CSMA/CD wynikających z 1Gbps. Są to naprawdę ciekawe zagadnienia, niemniej nadające się już bardziej do oddzielnego przedmiotu, zajmującego się historią komputerów i protokołów sieciowych. A my w końcu chcemy szkolić przyszłych techników czy inżynierów, a nie historyków.
Dlatego wystarczy wiedzieć, że w trybie Half Duplex w ramach jednego segmentu sieci mamy jedną domenę kolizyjną, a co za tym idzie może tam nadawać w danym momencie tylko jedna stacja. Mówimy o segmencie, gdy zakładamy zastosowanie urządzenia typu hub lub kabla koncentrycznego. Dlatego obecnie też warto dodać założenie, że mamy do czynienia zawsze z przełącznikiem, stąd ta domena objemie tylko jeden port przełącznika, który pracuje w trybie Half Duplex. Urządzeń typu hub czy też kabli koncentrycznych już od dawna się nie stosuje w technologii Ethernet, choć sam do takiej właśnie sieci Ethernet podpinałem swój pierwszy komputer. Przy Full Duplex obie strony połączenia mogą nadawać i nie dochodzi do kolizji. To tak w dużym uproszczeniu.
Warto pamiętać, że kolizje (ang. collision) są czymś naturalnym w trybie Half Duplex i nie należy ich uznawać za błędy. W przypadku zwykłej kolizji, interfejs sieciowy ponawia transmisję ramki. Dopiero spóźniona kolizja (ang. late collision) uznawana jest w trybie Half Duplex za błąd. Dochodzi wtedy do zgubienia ramki. Gdy połączenie pomiędzy dwoma urządzeniami nie działa zbyt dobrze, warto sprawdzić po obu jego stronach czy nie działa ono w trybie Half Duplex. Należy zrobić wszytko by zaczęło ono pracować w trybie Full Duplex. Obecnie nie używa się już w sieci urządzeń typu hub, stąd tryb Half Duplex nie powinien być stosowany. Nie należy również doprowadzić do tego by po jednej stronie połączenia port działał w trybie Full Duplex, a po drugiej stronie w trybie Half Duplex. Jest to jeden z przykładów, kiedy może dochodzić do spóźnionych kolizji i co za tym idzie gubienia ramek.
Dlatego warto podwójnie wszystko sprawdzić przy ręcznej konfiguracji prędkości i trybu Duplex na porcie przełącznika lub w interfejsie karty sieciowej komputera. Autonegocjacja została opracowana w 1995 roku, podczas gdy tryb Full Duplex w 1997.
Autonegocjacja korzysta z impulsów FLP (Fast Link Pulse), w których to zakodowane są informacje o obsługiwanych prędkościach i trybach pracy. Jeżeli jedna ze stron nie wysyła FLP, to znaczy że nie obsługuje autonegocjacji. Zatem druga strona połączenia sama musi określić swój tryb pracy. Wykrywanie równoległości (ang. parallel detection) w Ethernet jest w stanie wykryć po odebranych sygnałach prędkość z jaką pracuje druga strona. Natomiast nie da się w ten sposób ustalić tego czy druga strona pracuje w trybie Half Duplex czy Full Duplex. Dlatego też musimy coś założyć. W związku z tym, że autonegocjacja została opracowana przed trybem Full Duplex dużo interfejsów zakłada, że skoro coś nie obsługuje autonegocjacji to trybu Full Duplex tym bardziej i ustawia się wtedy zawsze w tryb Half Duplex. Wymaga tego też standard. Natomiast spotkaliśmy też takie karty sieciowe, co robią dokładnie odwrotnie i wybierają domyślnie najlepszy z dostępnych trybów, czyli Full Duplex. Zatem, niestety zależy to od producenta. W takich scenariuszach może dojść do niezgodności trybu Duplex, a co za tym idzie spóźnionych kolizji i gubienia ramek.
Warto zwrócić uwagę na daty, które znajdują się na slajdzie. Szczególnie na tę, kiedy powstał 1Gbps, a kiedy 10Gbps. Obecnie oczywiście mamy już dostępne o wiele większe prędkości, niemniej te wciąż są spotykane i dość popularne pomimo tylu lat.
W roku 1982 został opracowany Ethernet II (DIXv2.0). Jest to jeden z obecnie stosowanych formatów ramki Ethernet. Dalej standaryzacją technologii Ethernet zajęła się już organizacja IEEE. Skutkiem jej pracy w 1983 roku powstał wstępny standard IEEE 802.3, gdzie zmianie uległ nieco format ramki Ethernet. Konsorcjum DIX skupiło się na opracowaniu standardu, który będzie regulował każdy aspekt technologii Ethernet. Za to organizacja IEEE musiała wpasować tę technologię w grupę ogólnoświatowych standardów LAN/MAN oznaczonych numerkiem 802. Technologie te wykorzystywały do komunikacji z warstwami wyższymi już istniejącą podwarstwę LLC (Logical Link Control) opisaną w IEEE 802.2. Jest ona wspólna dla technologii z rodziny 802 i co za tym idzie nie jest formalnie częścią standardu 802.3. Jak już wcześniej zostało wspomniane, LLC jest górną podwarstwą warstwy łącza danych modelu OSI/ISO. Zatem pełni podobną rolę czy funkcję, jak pole "Type" oryginalnej ramki w formacie Ethernet II.
Budowa nagłówka LLC widoczna jest w prawym górnym rogu poniższego slajdu. Znajduje się on w ramce IEEE 802.3, jeżeli w polu "Type/Length" przenoszona jest wielkość pola danych (jest ono mniejsze lub równe maksymalnej wielkości ramki) - zostało to oznaczone czerwonym kolorem. Zatem format ramki Ethernet zdefiniowany w IEEE 802.3 jest zgodny z formatem Ethernet II. Niemniej nie było tak od samego początku. Dopiero w 1987 roku organizacja IEEE przemianowała pole "Length" na "Type/Length", zapewniając tym samym zgodność pomiędzy obiema formatami ramek. Jeżeli pole "Type/Length" zawiera długość pola danych, to w pierwszych oktetach pola danych znajdują się dane LLC. Ich zadaniem w technologii Ethernet jest wskazanie protokołu, którego dane są przenoszone w polu danych czyli protokołu warstwy wyższej. Zatem dane te wykorzystywane są w procesie enkapsulacji i dekapsulacji. My skupimy się tutaj tylko na tym, jak wygląda nagłówek LLC w typowym dla sieci Internet zastosowaniu.
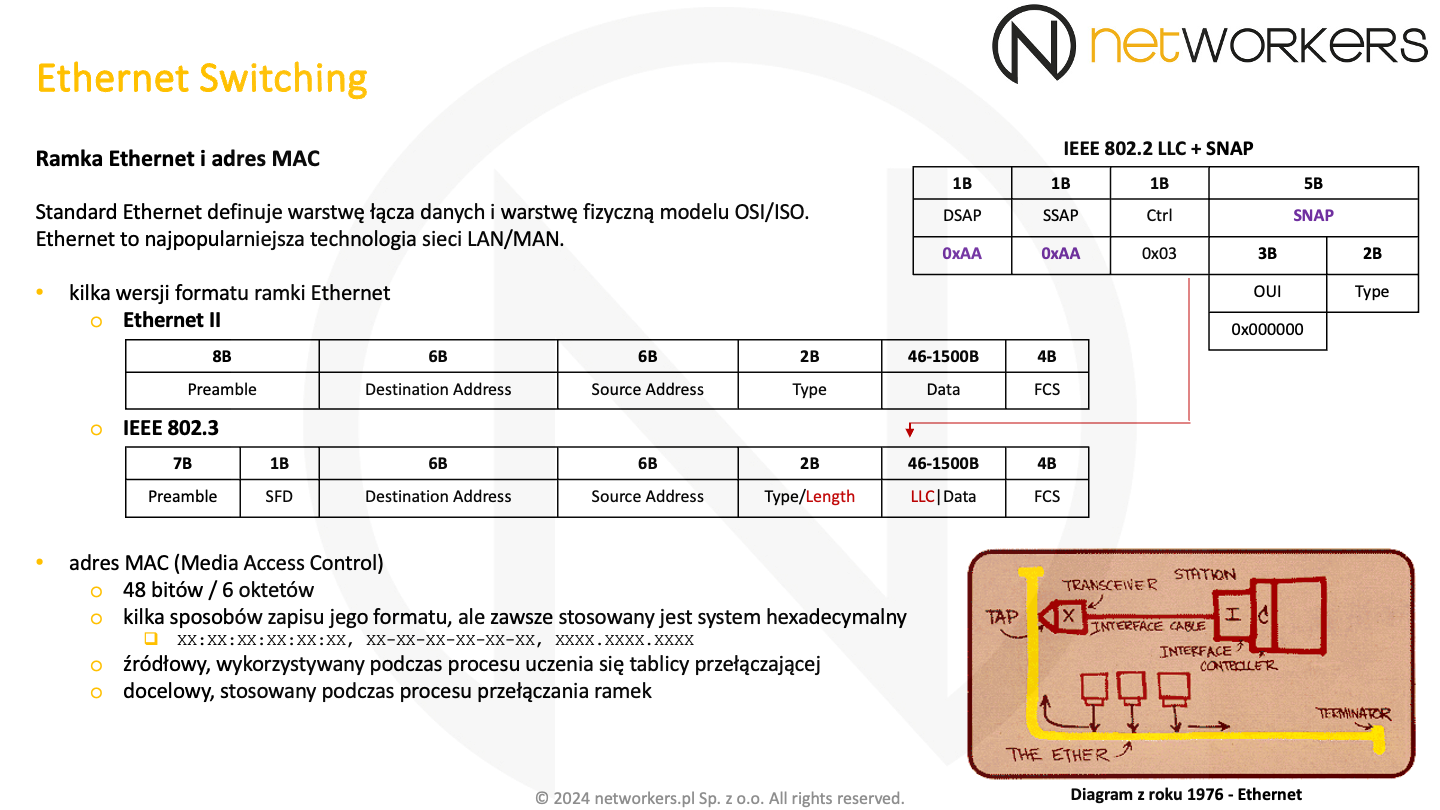
Dane LLC mogą mieć różną długość i co za tym idzie budowę. Znajduje się tam pole "Ctrl" (1-oktet w naszym zastosowaniu), którego wartość w naszym przypadku będzie zawsze wynosiła 0x03. Oznacza ona U PDU (Unnumbered PDU). Podwarstwa ta może pełnić o wiele więcej funkcji, w tym nawet zapewniać niezawodną transmisję i kontrolę przepływu na poziomie warstwy drugiej. Stąd mogą być tam stosowane też I PDU (Information PDU) oraz S PDU (Supervisor PDU). Niemniej my się zajmujemy tylko jej zastosowaniem w obszarze technologii Ethernet. Zatem mamy U PDU, gdzie znajduje się pole DSAP (Destination Service Access Point) i pole SSAP (Source Service Access Point). Pola te są stosowane do wskazania komunikujących się ze sobą warstw wyższych, stąd najczęściej są one takie same. Najczęściej, jako że w teorii podwarstwa ta umożliwia też wykorzystanie "grupowych DSAP" czy "rozgłoszeniowego DSAP" (Global DSAP). Stąd w teorii nie zawsze jest to prawdą. Warto zwrócić uwagę na to, że pole to ma tylko 1-oktet, podczas gdy pole "Type" w ramce Ethernet II ma aż 2-oktety. Stąd na pewno nie da się tam zmieścić tego samego. Dla przykładu nie ma wartości pola SAP dla protokołu ARP. Inna rzecz, że dobrze byłoby nie zużyć prawie całej dostępnej przestrzeni już na samym początku. Stąd organizacja IEEE zdecydowała się na wprowadzenie rozszerzenia SNAP (Sub-Network Access Protocol). Rozszerzenie to jest stosowane tylko, jeżeli pola DSAP i SSAP mają wartość 0xAA. Pole SNAP składa się z pola "OUI" i pola "Type". Jeżeli pole OUI składa się samych zer (ma wartość 0x000000), to wartości następującego po nich pola "Type" są zgodne z polem "Type" w ramce Ethernet II i zarządza nimi organizacja IANA (Internet Assigned Numbers Authority).
Producenci urządzeń do sieci Ethernet otrzymują własne OUI (Organizationally Unique Identifier), które potem trafia do pierwszych 3-oktetów adresów MAC interfejsów sieciowych ich produktów. Zatem każdy z producentów może też tworzyć swoje własnościowe protokoły i samodzielnie zarządzać przydziałem numerów w ramach własnego pola "Type", które mieści się w nagłówku LLC+SNAP. To oczywiście pod warunkiem, że znajdujące się tam pole OUI ma jego wartość.
Użycie LLC+SNAP w technologii Ethernet zostało opisane również w RFC 1042. Jest to opis bardzo zawężony do tego jednego zastosowania. Jeżeli LLC interesuje kogoś bardziej, to na pewno nieporównywalnie więcej znajdzie w standardach IEEE 802.2.
Na początku ramki Ethernet znajduje się preambuła. Była ona niezbędna w sieci Ethernet pracującej z prędkością 10Mbps, gdzie układy odbiorcze potrzebowały trochę czasu na wykrycie faktu pojawienia się nowej ramki i przygotowania się do jej odbioru. W ten sposób o ile początek preambuły mógł zostać utracony, to cała reszta była odbierana w całości. W formacie Ethernet II widać, że preambuła ma 8-oktetów (64-bity) podczas, gdy w formacie IEEE 802.3 widać, że te 8-oktetów zostało rozdzielone na dwa pola. Pierwsze 7-oktetów (56-bitów) o tej samej nazwie "Preamble" i drugie 1-oktet (8-bitów) określone jako SFD od Start Field Delimiter. Tak naprawdę te 8-oktetów czy 64-bity ma taką samą wartość bitową. Są to naprzemian występujące 1 i 0, gdzie dwa ostatnie bity ostatniego oktetu mają zawsze wartość 11. Zatem pierwsze 7-oktetów ma wartość 10101010, a ostatni 1-oktet wartość 10101011. Te dwa ostatnie bity oznaczają, że za nimi zaczyna się już ta właściwa część ramki, która musi zostać w całości odebrana.
Przy prędkościach 100Mbps, 1Gbps i większych, preambuła nie jest już potrzebna. Wyższe prędkości stosują stałą sygnalizację oraz odpowiednie symbole kodowe oznaczające początek i koniec ramki. Pola te zostały zachowane ze względu na zgodność wsteczną. Dodatkowo pomiędzy transmisją każdej kolejnej ramki Ethernet stosowana jest przerwa międzyramkowa IFG (Inter Frame Gap), która jest równa czasowi transmisji 96-bitów. Zatem im szybsza technologia, tym ta przerwa jest krótsza.
Pole docelowego adresu MAC ("Destination Address") stosowane jest podczas procesu przełączania. Zaraz po nim znajduje się źródłowy adres MAC ("Source Address"), który stosowany jest podczas procesu uczenia się tablicy przełączającej przełącznika. Adresy te wskazują skąd i dokąd zaadresowana jest ramka. Adres MAC składa się z 6-oktetów (48-bitów) i zapisywany jest heksadecymalnie. Przy czym stosuje się różne formaty jego zapisu. W przypadku routerów i przełączników firmy Cisco Systems można spotkać zapis, w którym każde 2-oktety odseparowane są kropką ".". W systemach z rodziny Microsoft Windows każdy oktet odseparowany jest pauzą "-". A w systemach z rodziny GNU/Linux każdy oktet odseparowany jest dwukropkiem ":". Adres MAC składa się z dwóch części. Pierwsze 3-oktety (24-bity) to tak zwane OUI (Organizationally Unique Identifier). Każdy z producentów urządzeń do sieci Ethernet ma swoje unikalne 24-bitowe ciągi OUI. Kolejne 24-bity określane są już przez danego producenta. W ten sposób powstaje adres MAC, który w ramach danego segmentu sieci musi unikalnie identyfikować każdą stację.
Dalej znajduje się pole "Type/Length", a po nim opcjonalnie nagłówek LLC i właściwe dane, o których pisaliśmy wyżej.
Dla zwykłej ramki Ethernet minimalna i maksymalna ilość danych to odpowiednio 46 i 1500 oktetów. Ta minimalna wielkość powiązana jest z pracą w trybie Half Duplex, gdzie wymogiem jest by transmisja ramki trwała na tyle długo, by kiedy dojdzie do kolizji nawet w najdalszym możliwym odcinku segmentu sieci, sygnał o kolizji zdążył wrócić przed jej pełnym wytransmitowaniem. Wartość ta powiązana jest z maksymalną długością segmentu Ethernet i tak zwanym czasem "slot time", który równy jest czasowi transmisji 512-bitów dla trybu Half Duplex w 10/100Mbps. Dzięki temu interfejs może wykryć fakt kolizji i ponowić wysyłanie ramki w późniejszym terminie. Należy pamiętać, że Ethernet nie stosuje potwierdzeń, więc taki mechanizm był niezbędny. Jeżeli danych jest mniej, to dodawane jest do ramki wypełnienie do 46-oktetów.
Na końcu ramki znajduje się 32-bitowe pole FCS (Frame Check Sequence). Zawiera ono sumę CRC (Cyclic Redundancy Checksum), która stosowana jest do weryfikacji integralności. Suma ta obejmuje docelowy i źródłowy adres MAC, pole "Type/Length" oraz całe pole danych ramki Ethernet. Stacja odbierająca może porównać swój wynik wyliczenia CRC z tym, jaki znajduje się w ramce by sprawdzić, czy ramka nie została uszkodzona w trakcie transmisji przez sieć.
Do rozmiaru ramki nie wlicza się pól "Preamble" i "SFD". Zatem maksymalny rozmiar normalnej ramki Ethernet razem z jej nagłówkiem wynosi 1518-oktetów (18-oktetów to nagłówek Ethernet).
W roku 1976 Robert Metcalfe narysował diagram obrazujący technologię Ethernet, który widoczny jest w prawym dolnym rogu powyższego slajdu. Wtedy też technologia Ethernet została pierwszy raz zaprezentowana światu.
Zajmiemy się teraz interfejsem zależnym od medium, czyli MDI (Media Dependent Interface). Jako że medium, o którym tutaj mówimy, jest typowa skrętka czy kabel UTP, to MDI będzie ośmiostykowym złączem nazywanym również złączem RJ45 czy bardziej poprawnie 8P8C (8 Position 8 Contact) - 8 miejsc na styki i 8 styków. Jest ono widoczne w prawym dolnym rogu poniższego slajdu.
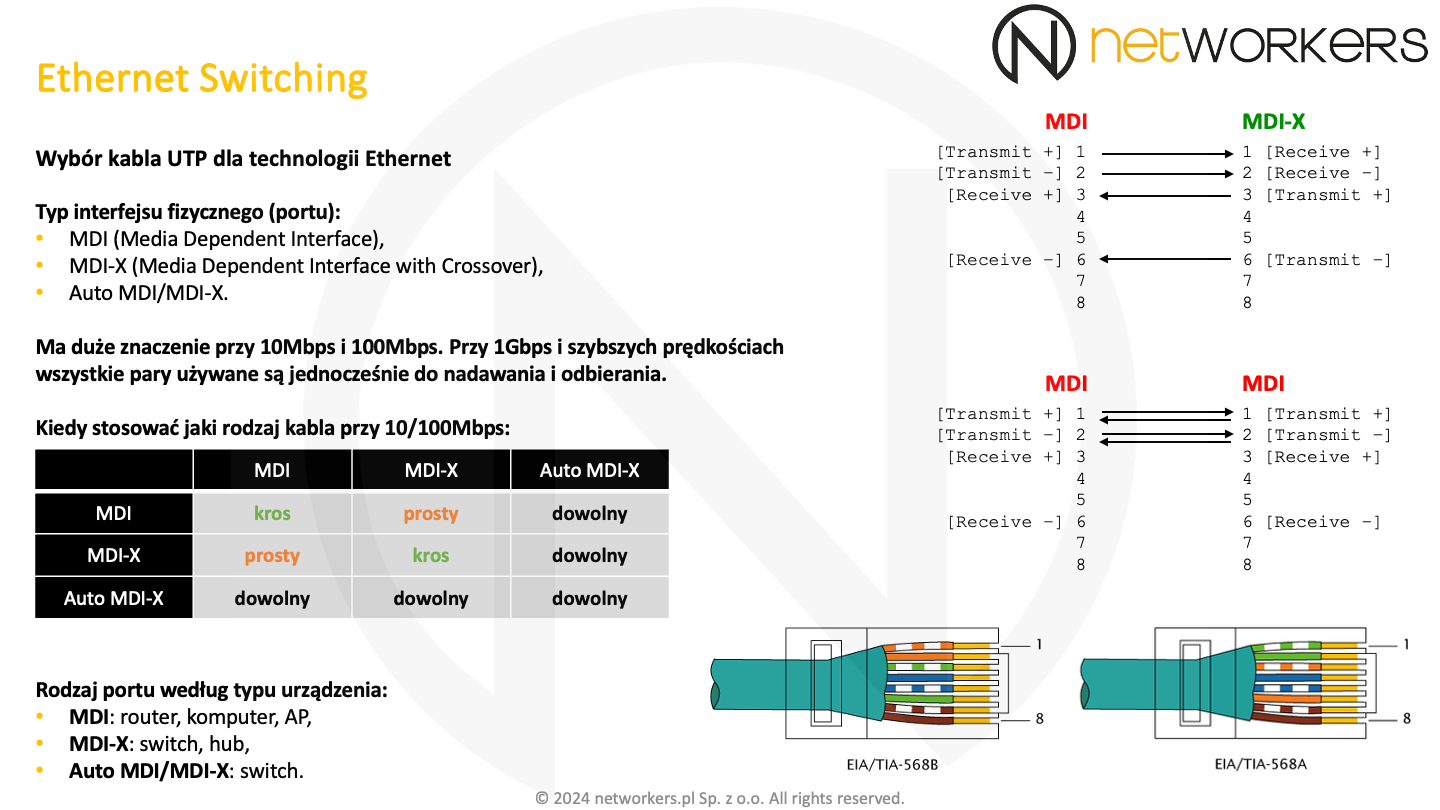
Mówimy o nim, jako że w salach szkoleniowych bardzo często korzysta się z kabli UTP i też często mamy do czynienia ze starszymi urządzeniami, które mają porty 10/100Mbps. Przy szybszych prędkościach nie ma dużego znaczenia jaki rodzaj kabla zostanie użyty, ponieważ wszystkie pary przewodów wykorzystywane są zarówno do transmisji w obie strony, jak i odbioru. Natomiast przy 10/100Mbps używane są tylko dwie z czterech par i na dodatek każda odpowiada za transmisję danych w innym kierunku.
Interfejs MDI jaki zwykle znajduje się w routerach, kartach sieciowych komputerów czy punktach dostępowych Wi-Fi, na pinie pierwszym i drugim transmituje dane, a na pinie 3 i 6 je odbiera. Zatem jeżeli użyjemy do połączenia dwóch interfejsów MDI kabla prostego, to transmisja z pinów 1 i 2 dotrze do pinów 1 i 2 drugiej strony. A one nie służą do odbioru. Natomiast na pinach 3 i 6, które służą do odbioru nic się nie pojawi. Analogicznie będzie z dwoma interfejsami typu MDI-X. Dlatego przy dwóch interfejsach tego samego typu należy stosować kabel krosowy. Kabel krosowy to taki, gdzie po jednej stronie stosuje się zakończenie zgodne z EIA/TIA-568B, a po drugiej z EIA/TIA-568A. Kabel prosty to taki, który z obu stron zakończony jest w ten sam sposób, zwykle z użyciem EIA/TIA-568B. Standardy ten definiują m.in. kolejność przewodów w złączu modułowym 8P8C czy inaczej RJ45.
Do łączenia urządzeń w sieci Ethernet wykorzystywane są urządzenia nazywane przełącznikami lub z angielskiego switchami. Każdy z portów przełącznika tworzy oddzielną domenę kolizyjną i umożliwia transmisję z pełną prędkością portu, równolegle w obu kierunkach. Zatem pracuje w trybie Full Duplex. Należy jednak pamiętać, że zarówno tryb pracy portu (Full Duplex/Half Duplex), jak i jego prędkość podlegają negocjacji i mogą zostać ustawione statycznie.
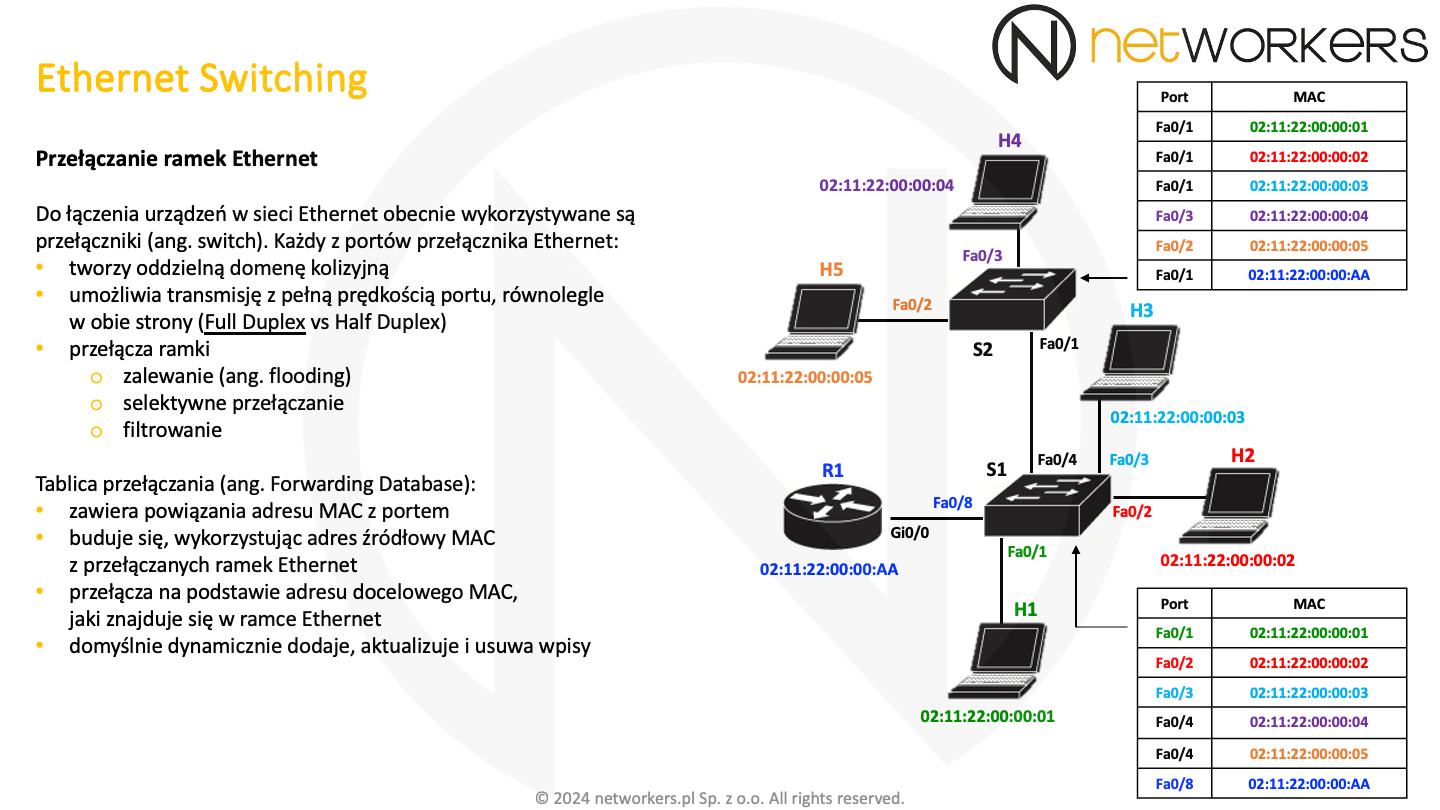
Przełączanie ramek realizowane jest z użyciem docelowego adresu MAC. W procesie tym wyróżniamy zalewanie, które polega na wysyłaniu ramki na wszystkie porty oprócz tego, na którym została odebrana. Zalewanie ma miejsce w przypadku ramek rozgłoszeniowych, w niektórych przypadkach ramek grupowych oraz gdy tablica przełączająca nie zna danego adresu MAC. Do selektywnego przełączania dochodzi, gdy tablica przełączająca jest nauczona i wie dokładnie na który port ma przełączyć ramkę. Zatem selektywne przełączanie polega na precyzyjnym przekazaniu ramki tylko na określony port. Filtrowanie polega na nieprzekazywaniu ramki do innych segmentów. Najczęściej dochodzi do tego, kiedy adres docelowy według tablicy przełączającej znajduje się za portem, na którym została odebrana ramka. Wtedy nie ma sensu jej przekazywać nigdzie indziej.
Na naszym slajdzie widać z prawej strony dwie tabele, odzwierciedlające zawartość tablic przełączających. Tablica taka zawiera powiązania adresu MAC z portem przełącznika. Budowana jest z użyciem źródłowych adresów MAC przełączanych ramek. Domyślnie budowanie jej zawartości odbywa się dynamicznie, niemniej można to zmienić. Można dodawać do niej wpisy ręcznie.
Każdy interfejs podłączony do sieci analizuje minimum pole docelowego adresu MAC w odebranych ramkach Ethernet. Oczywiście nie docierają do niego wszystkie ramki. Jeżeli tym adresem MAC jest jego adres, adres rozgłoszeniowy, lub któryś z obsługiwanych przez niego adresów grupowych, to kontynuuje odbieranie i przetwarzanie ramki.
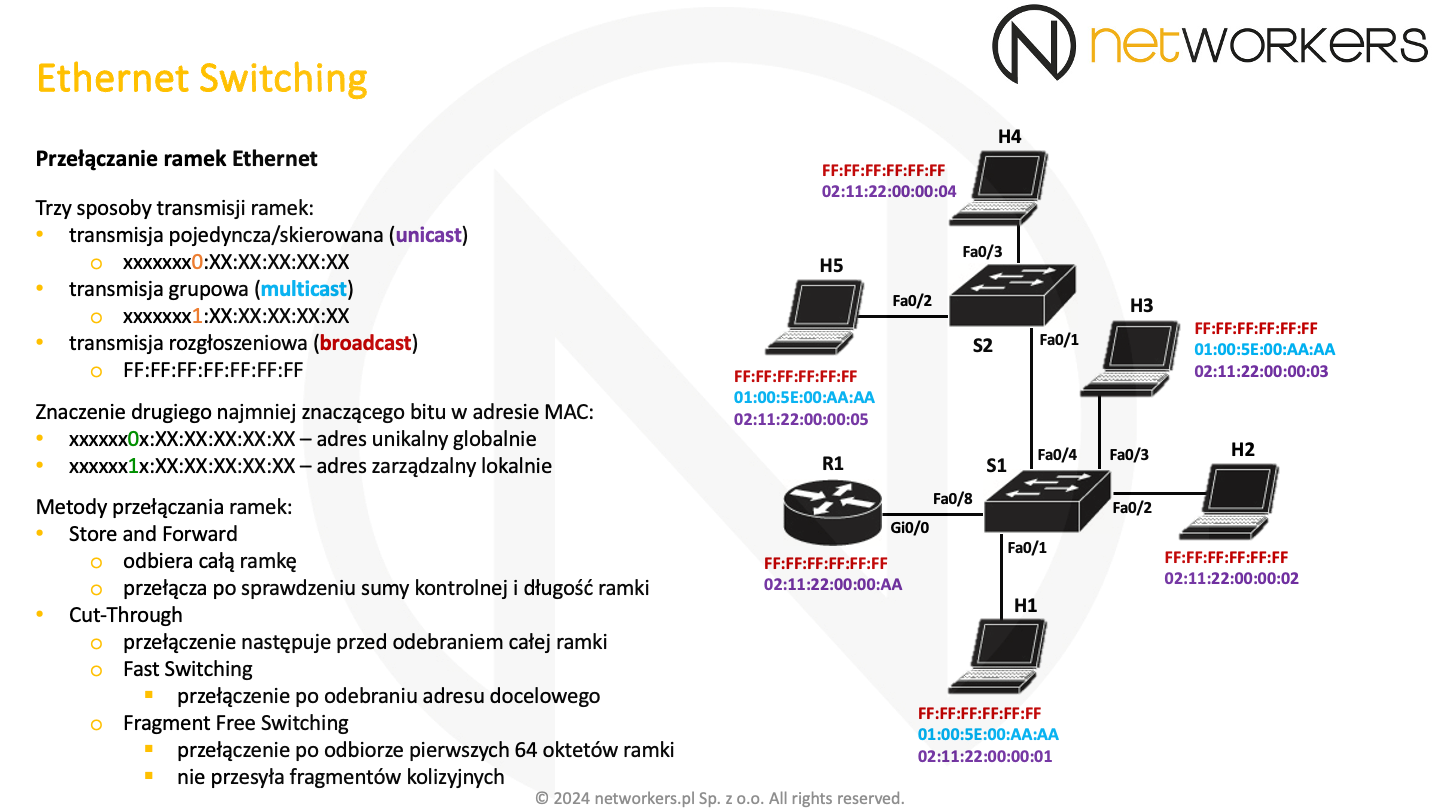
Najmniej znaczący bit pierwszego oktetu docelowego adresu MAC jest transmitowany do sieci jako pierwszy. Poszczególne oktety adresu są transmitowane w kolejności występowania od lewej do prawej. Natomiast bity w oktecie od najmniej do najbardziej znaczącego. Jeżeli wartość tego najmniej znaczącego bitu pierwszego oktetu wynosi 0, to mamy do czynienia z adresem pojedynczego urządzenia lub inaczej adresem skierowanym (ang. unicast). Kiedy ma on wartość 1 to oznacza, iż jest to jakiś rodzaj adresu grupowego, zatem jest to adres grupowy (ang. multicast) lub adres rozgłoszeniowy (ang. broadcast).
Jeżeli drugi najmniej znaczący bit pierwszego oktetu adresu MAC jest ustawiony na 1 oznacza to, że nie jest to globalnie unikalny adres MAC. Adres globalny to ten fizycznie nadany i przypisany przez producenta do interfejsu. Kiedy chcemy samodzielnie przypisywać w naszej sieci adresy MAC należy pamiętać o tym, by ten bit miał wartość 1. Wtedy nie dojdzie do konfliktu z adresami unikalnymi globalnie, które mają ten bit ustawiony na 0. Dla przykładu adresy MAC postaci: X2:XX:XX:XX:XX:XX, X6:XX:XX:XX:XX:XX, Xa:XX:XX:XX:XX:XX i Xe:XX:XX:XX:XX:XX, to adresy administrowane lokalnie, jako że w pierwszym oktecie drugi najmniej znaczący bit ma wartość 1. Podczas gdy adresy MAC: X0:XX:XX:XX:XX:XX, X4:XX:XX:XX:XX:XX, X8:XX:XX:XX:XX:XX i Xc:XX:XX:XX:XX:XX są adresami unikalnymi globalnie. Oba najmniej znaczące bity pierwszego oktetu zostały oznaczone na slajdzie odpowiednimi kolorami.
Dostępne są dwie główne metody przełączania ramek. Najbardziej popularną jest Store and Forward, która odbiera całą ramkę, sprawdza jej długość i sumę kontrolną, a następnie jeżeli wszytko jest z nią w porządku dokonuje przełączenia. Metoda ta nie propaguje fragmentów kolizyjnych i uszkodzonych ramek do innych segmentów sieci.
Metoda Cut-Through ma dwa tryby i realizuje przełączanie o wiele szybciej. W trybie Fast Switching przełączenie następuje zaraz po odebraniu adresu docelowego, a w trybie Fragment Free Switching po odebraniu pierwszych 64-oktetów ramki co gwarantuje, że nie przełączamy fragmentów kolizyjnych. Jest to szczególnie istotne przy pracy w trybie Half Duplex.
Zawartość tablicy przełączającej można wyświetlić z użyciem polecenia "show mac address-table". W kolumnie "Type" widać czy adres został do niej dodany przez system lub nas statycznie, czy też został on nauczony w sposób dynamiczny z użyciem źródłowego adresu MAC. Ostatnia kolumna zawiera nazwę portu, z którym powiązany jest dany adres MAC.

Ramki zaadresowane do adresów MAC ze wskazanym portem "CPU" są przetwarzane przez przełącznik. Są to najczęściej ramki zaadresowane do protokołów sieciowych, jakie działają na przełączniku.
W sieci produkcyjnej zawartość tablicy przełączającej przełącznika potrafi być bardzo długa i często trudno w niej szybko znaleźć to co nas interesuje. Stąd istnieją dodatkowe parametry polecenia trybu Privileged EXEC: "show mac address-table", z użyciem których możemy zawęzić wyświetlane z niej informacje.

Jak widać na slajdzie, do zawężania wyświetlanych informacji można użyć zarówno adresu MAC, jak i interfejsu czy VLAN.
Istnieje możliwość ręcznego usuwania wpisów z tablicy przełączającej przełącznika. Służy do tego polecenie trybu Privileged EXEC: "clear mac address-table dynamic", dzięki któremu można z niej usnąć zarówno wszystko, jak i pojedyncze wpisy.

Polecenie to posiada dodatkowe parametry, z użyciem których możemy wskazać bardziej precyzyjnie to, co chcemy z niej usunąć.
Z każdym dynamicznie utworzonym wpisem tablicy przełączającej powiązany jest licznik starzenia się. Domyślnie jego wartość wynosi 300 sekund. Kiedy doliczy on do zera, wpis jest usuwany. Jego wartość jest resetowana z każdą odebraną ramką, której adres źródłowy MAC pokrywa się z istniejącym wpisem. Przy czym, jeżeli ten adres źródłowy pojawi się na innym porcie, to dochodzi do aktualizacji wpisów. Skutkiem tego stara informacja jest natychmiast usuwana i tworzony jest nowy wpis z aktualnym portem.

Do weryfikacji czasu starzenia się wpisów służy polecenie "show mac address-table aging-time". Czas ten można zmodyfikować z użyciem polecenia trybu konfiguracji globalnej: "mac address-table aging-time".
Tablica przełączająca ma skończoną pojemność, która zależna jest od platformy. Jej wielkość można sprawdzić z użyciem polecenia "show mac address-table count". Uruchomienie niektórych funkcjonalności może nakładać na jej wielkość dodatkowe limity.

Kiedy dojdzie do zapełnienia tablicy przełączającej, przełącznik nie jest w stanie precyzyjnie przekazywać wszystkich ramek. Ruch do adresów znajdujących się już w tablicy może być oczywiście przekazywany według wpisu na konkretny port. Natomiast ruch do adresów dla których brakło miejsca, będzie przekazywany na wszystkie porty za wyjątkiem portu, z którego przyszedł.
Przed kolejną porcją wiedzy zachęcamy do przećwiczenia i utrwalenia tej poznanej tutaj. Skorzystaj z naszych ćwiczeń!
W trakcie ćwiczeń warto dokładnie przeanalizować wszystkie omówione tutaj pola ramki Ethernet zwracając także uwagę na to, kiedy w sieci pojawiają się ramki w formacie Ethernet II, a kiedy w formacie IEEE 802.3. Powinniśmy móc wyłapać i takie i takie. Warto zwrócić uwagę zarówno na ramki generowane przez komputer, jak i te generowane przez urządzenia sieciowe, analizując po kilka różnych pakietów z każdego typu. Najlepiej wykorzystać do tego program Wireshark.
Zachęcamy również do sprawdzenia wpływu niezgodności trybu Duplex (Half Duplex i Full Duplex) na prędkość transmisji oraz weryfikację błędów jakie pojawiają się w tym czasie na interfejsach.